Why do all LLMs need structured output modes?
By Fireworks.ai|2/20/2024
Tl;dr: All Fireworks language models can now be invoked with either a (a) JSON schema (b) context-free grammar (similar to Llama.cpp’s feature) to guarantee that LLM output strictly follows your desired format without hallucinations.
Intro
Since ReAct and Gorilla, there have been tentative explorations into tool use for both chatbots and agents. However they were not reliable or scalable and mostly constrained to research, until OpenAI launched ChatGPT plugins last March and then innovated the function calling API in June, becoming the most widely adopted way for LLMs to generate JSON, initially only for function calling, but formalized as an official “JSON Mode” API in November. However, this is only available in OpenAI’s closed platform.
Simultaneously, explorations in constraining LLM output proceeded both in academia (ReLLM, GCD) and industry (guidance, guardrails, outlines), The most flexible and widely used version of LLM constraints eventually came out of Llama.cpp’s grammar-based-sampling feature. However, this was only available locally on certain supported llama.cpp models.
We believe that structured output modes for LLMs have gone from research prototypes in 2023 to table-stakes in 2024. Ensuring that LLMs respond with predictable, parsable output is critical to many use cases. For example, if you’re using an LLM to generate arguments for an API call, you always want the model to respond with a specific API schema. If you’re using an LLM to tag text, you might always want to use the same labels. Developers can spend hours perfecting a system prompt to “only respond in valid JSON'' or “respond in less than 500 words” and still get unintended output. With function calling, you can build even more complex AI engineering abstractions, resulting in leading developers concluding that Pydantic is all you need and Structured Data is the best way to do Chain of Thought.
What we’re doing about it
Today, we’re launching of two features on all Fireworks language models:
-
JSON mode - Always generate valid JSON according to a provided schema
-
Structured grammar mode - Always generate valid output according to arbitrary context-free grammar for maximum flexibility. We take inspiration from the popular grammar feature in Llama.cpp. As we understand, we’re the only hosted model API provider supporting this feature!
Use both features on the Fireworks generative AI platform to get blazing fast inference and battle-tested reliability!
JSON mode
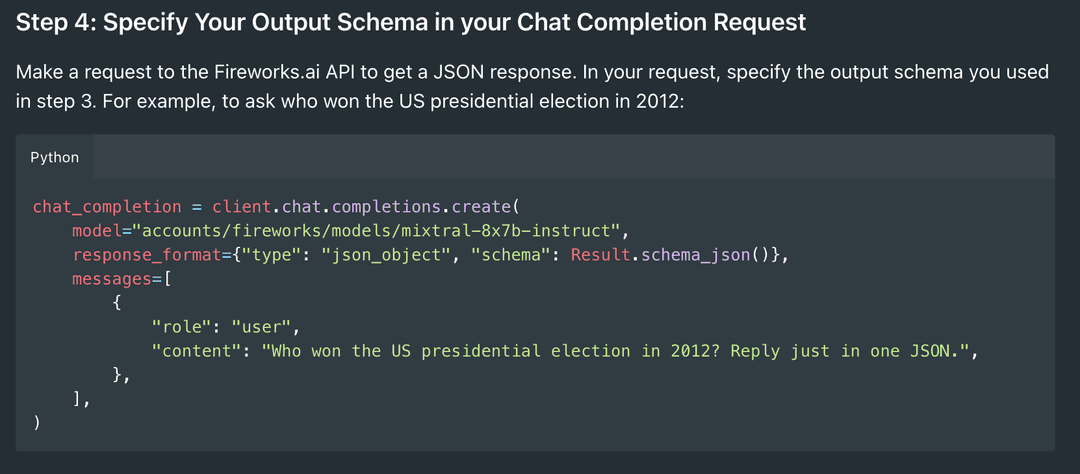
JSON mode enables users to define a JSON output schema for the model to follow. In Python, you can get the schema from any Pydantic structure. Similarly, it can be generated from a TypeScript structure.
JSON mode allows you to better use any of our models for function calling or other structured output. For example, if you were using the Fireworks Mixtral model to tag characteristics from an email, you would first define the schema you’d want to output. In this example, that might be: '''json class Tag(BaseModel): language: str sentiment: str topic: str ''' We would then specify this output schema when we call the model by specifying it as the response. Note that we also still describe the output format in the prompt.
chat_completion = client.chat.completions.create(
model="accounts/fireworks/models/mistral-7b-instruct-4k",
response_format={"type": "json_object", "schema": Tag.schema_json()},
messages=[
{
"role": "system",
"content": "Given an email, classify the email's language, sentiment and topic in JSON.",
},
{
"role": "user",
"content": "Looking forward to meeting next Friday! We’ll come prepared with a proposal for project scoping. Can’t wait to discuss with you!",
},
],
)The model would then respond according to the specified JSON schema. In this example, we get the output:
'{\n "language": "English",\n "sentiment": "Positive",\n "topic": "Meeting to discuss project scoping"\n}'Voila! Every time you call the model, you can rest assured that the output will fit your JSON schema.How does it work? What’s happening behind the scenes is that we’re taking the scheme you provide and forcing the model to decode according to its structure. For each step of the autoregressive decoding, we only allow new tokens to be generated that would be considered valid in the provided schema. See our documentation for more information on how JSON mode works and how to use it!
Important: when using JSON or Grammar mode, it's crucial also to instruct the model to produce the desired schema via a system or user message. The description in the prompt may be the same formal schema or it can be in natural language.
Grammar mode
Outputting JSON is great but not all rules/structure can fit neatly in JSON. Grammar mode lets you describe the desired context-free grammar in an extended BNF form. The possibilities are endless! Anything from output styles to entire programming languages can be represented as grammars. Let’s take a few examples.
Use case #1
Let’s say you want to make use of a mistral model to make an initial medical diagnosis. (NOTE: Fireworks does not intend to give medical advice). In this example, you’d want to limit the medical diagnosis to just the name of 1 of 5 conditions. Here is what the grammar would look like:
`root` `::= ` `diagnosis`
`diagnosis` `::=` `"arthritis"` `|` `"dengue"` `|` `"urinary` `tract` `infection"` `|` `"impetigo"` `|` `"cervical` `spondyl`The root rule is what the entire output has to match. We define the root rule to be just the diagnosis rule. And for diagnosis, we defined it to be one of the five different classes, each separated with a | to signify that it can be any of these words.
from fireworks.client import Fireworks
<!---->
client = Fireworks(
api_key="<your-api-key>",
)
<!---->
diagnosis_grammar = """
root ::= diagnosis
diagnosis ::= "arthritis" | "dengue" | "urinary tract infection" | "impetigo" | "cervical spondylosis"
"""
<!---->
chat_completion = client.chat.completions.create(
model="accounts/fireworks/models/mistral-7b-instruct-4k",
response_format={"type": "grammar", "grammar": diagnosis_grammar},
messages=[
{
"role": "system",
"content": "Given the symptoms try to guess the possible diagnosis. Possible choices: arthritis, dengue, urinary tract infection, impetigo, cervical spondylosis. Answer with a single word",
},
{
"role": "user",
"content": "I have been having trouble with my muscles and joints. My neck is really tight and my muscles feel weak. I have swollen joints and it is hard to move around without becoming stiff. It is also really uncomfortable to walk.",
},
],
)
print(chat_completion.choices[0].message.content)Note, that we also described the output format in the prompt in free form. Alternatively, could have used a fine-tuned model for the medical domain.
You can see the response was “arthritis” - the model responded with only the name of the medical condition, exactly as we had specified.
'arthritis'
What happens if we use the prompt without the grammar? Output is often chattier, like in this real example: “The possible diagnosis for these symptoms could be arthritis.”
Use case #2
The fact that LLMs can generate output in multiple languages but what if we only want responses in one language? For example, let’s say we’re building a Japanese-speaking tour guide and only want Japanese output. This can also be represented in a grammar.
# Showing openai client here for full compatibility. Fireworks client example in the comments
`import` `openai`
`client` `=` `openai.OpenAI(`
`base_url="https://api.fireworks.ai/inference/v1",`
`api_key="YOUR API KEY",`
)
`japanese_grammar` `=` `"""`
`root` `::=` `jp-char+` `([` `\t\n]` `jp-char+)*`
`jp-char` `::=` `hiragana` `|` `katakana` `|` `punctuation` `|` `cjk`
`hiragana` `::=` `[ぁ-ゟ]`
`katakana` `::=` `[ァ-ヿ]`
`punctuation` `::=` `[、-〾]`
`cjk` `::=` `[一-鿿]`
"""
`chat_completion` `=` `client.chat.completions.create(`
`model="accounts/fireworks/models/mixtral-8x7b-instruct",`
`response_format={"type":` `"grammar",` `"grammar":` `japanese_grammar},`
`messages=[`
`{`
`"role":` `"user",`
`"content":` `"You` `are` `a` `Japanese` `tour` `guide` `who` `speaks` `fluent` `Japanese.` `Please` `tell` `me` `what` `are` `some` `good` `places` `for` `me` `to` `visit` `in` `Kyoto?",`
`},`
`],`
)
print(chat_completion)Here the grammar is a little more sophisticated. We are saying there are multiple parts to the Japanese language, there is hiragana, katakana, punctuations and all the other possible CJK (Chinese, Japanese and Korean) characters. And then we go on to specify all the different character ranges for these concepts. Note that not all CJK is actually not valid Japanese. But with the help of grammar, the output is entirely Japanese text, adhering to the specified grammar.
`'こんにちは、私は日本語を母国語として話せるキョトの私が案内する旅行案内者です。京都を旅行にお付き合いいただきありがとうごさいます。京都にはたくさんの楽しいところがありますが、私はあなたの需要に基いて、いくつかのおすすめていきます。\n最初に、古都の一面を体感できる場所として、清水寺をおすすめします。清水寺は世界的に有名な寺院で、美しい金面山だまのホームページと、きれいな庭で知られています。\n次に、京',` And since the grammar is actually more lenient than Japanese and covers Chinese as well, we can also just prompt the model to be a fluent Chinese speaker.
`You` `are` `a` `Japanese` `tour` `guide` `who` `speaks` `fluent` `Chinese.` `Please` `tell` `me` `what` `are` `some` `good` `places` `for` `me` `to` `visit` `in` `Shanghai?",`And you can see here that we are trying something a little difficult, asking a Japanese tour guide to speak Chinese. But with the help from the grammar, the model replied in Chinese, with the same grammar specified
当您访问上海时、我建议您参观以下几个地方。\n上海外国语大学。这是一所著名的大学、校园美景优秀、还有各种餐馆可供您选择。\n上海中山公园。这是一座位于城市中心的公园、风景优美、有许多古老的建设和展览馆。\n南京路。这是一条繁华的商业大街、有许多品牌商店和餐馆可供您选择。\n上海南京东路步行街。这是全球最大的步行街之一、有许多商店和餐馆可供您选择。\n上海世博中心。这是一座展览馆复合体、经常举办各种展览和会议Without the help from the grammar, here is the model reply in a mix of Chinese and English
`你好!uming` `as` `a` `Japanese` `tour` `guide` `who` `speaks` `fluent` `Chinese,` `I` `would` `be` `happy` `to` `recommend` `some` `places` `for` `you` `to` `visit` `in` `Shanghai!\n\n1.` `The` `Bund:` `This` `is` `a` `famous` `waterfront` `area` `in` `Shanghai` `that` `offers` `stunning` `views` `of` `the` `city's` `skyline,` `including` `the` `iconic` `Oriental` `Pearl` `Tower.` `You` `can` `take` `a` `leisurely` `stroll` `along` `the` `promenade` `and` `enjoy` `the` `beautiful` `scenery.\n\n2.` `Yuyuan` `Garden:` `This` `is` `a` `beautiful` `classical` `Chinese` `garden` `that` `dates` `back` `to` `the` `Ming` `Dynasty.` `It` `features` `pavilions,` `halls,` `rockeries,` `ponds,` `and` `cloisters,` `and` `is` `a` `great` `place` `to` `experience` `traditional` `Chinese` `architecture` `and` `garden` `design.\n\n3.` `Shanghai` `Tower:` `This` `is` `the` `tallest` `building` `in` `China` `and` `the` `second-tallest` `building` `in` `the` `world.` `You` `can` `take` `the` `elevator` `up` `to` `the` `observation` `deck` `on` `the` `128th` `floor` `for` `breatht`So we see this as a powerful tool for programmers to have more constrained and stronger system prompts for the model to follow.
Use case #3 - programming language:
GBNF grammar can be more complicated. This is a llama.cpp example, the grammar describes what words/symbols are allowed, in this case, it's all valid C.
`import` `openai`
`client` `=` `openai.OpenAI(`
`base_url="https://api.fireworks.ai/inference/v1",`
`api_key="YOUR FIREWORKS API KEY",`
)
`c_grammar` `=` `"""`
`root` `::=` `(declaration)*`
`declaration` `::=` `dataType` `identifier` `"("` `parameter?` `")"` `"{"` `statement*` `"}"`
`dataType` `::=` `"int"` `ws` `|` `"float"` `ws` `|` `"char"` `ws`
`identifier` `::=` `[a-zA-Z_]` `[a-zA-Z_0-9]*`
`parameter` `::=` `dataType` `identifier`
`statement` `::=`
`(` `dataType` `identifier` `ws` `"="` `ws` `expression` `";"` `)` `|`
`(` `identifier` `ws` `"="` `ws` `expression` `";"` `)` `|`
`(` `identifier` `ws` `"("` `argList?` `")"` `";"` `)` `|`
`(` `"return"` `ws` `expression` `";"` `)` `|`
`(` `"while"` `"("` `condition` `")"` `"{"` `statement*` `"}"` `)` `|`
`(` `"for"` `"("` `forInit` `";"` `ws` `condition` `";"` `ws` `forUpdate` `")"` `"{"` `statement*` `"}"` `)` `|`
`(` `"if"` `"("` `condition` `")"` `"{"` `statement*` `"}"` `("else"` `"{"` `statement*` `"}")?` `)` `|`
`(` `singleLineComment` `)` `|`
`(` `multiLineComment` `)`
`forInit` `::=` `dataType` `identifier` `ws` `"="` `ws` `expression` `|` `identifier` `ws` `"="` `ws` `expression`
`forUpdate` `::=` `identifier` `ws` `"="` `ws` `expression`
`condition` `::=` `expression` `relationOperator` `expression`
`relationOperator` `::=` `("<="` `|` `"<"` `|` `"=="` `|` `"!="` `|` `">="` `|` `">")`
`expression` `::=` `term` `(("+"` `|` `"-")` `term)*`
`term` `::=` `factor(("*"` `|` `"/")` `factor)*`
`factor` `::=` `identifier` `|` `number` `|` `unaryTerm` `|` `funcCall` `|` `parenExpression`
`unaryTerm` `::=` `"-"` `factor`
`funcCall` `::=` `identifier` `"("` `argList?` `")"`
`parenExpression` `::=` `"("` `ws` `expression` `ws` `")"`
`argList` `::=` `expression` `(","` `ws` `expression)*`
`number` `::=` `[0-9]+`
`singleLineComment` `::=` `"//"` `[^\n]*` `"\n"`
`multiLineComment` `::=` `"/*"` `(` `[^*]` `|` `("*"` `[^/])` `)*` `"*/"`
`ws` `::=` `([` `\t\n]+)`
"""
`chat_completion` `=` `client.chat.completions.create(`
`model="accounts/fireworks/models/mistral-7b-instruct-4k",`
`response_format={"type":` `"grammar",` `"grammar":` `c_grammar},`
`messages=[`
`{`
`"role":` `"user",`
`"content":` `"You` `are` `an` `expert` `level` `C` `programmer.` `Give` `me` `a` `simple` `short` `example` `program.",`
`},`
`],`
)
print(chat_completion)And then you can see our little mistral model came up with an ugly but correct C program
char
`c(int` `a){return` `2*a;}`Enabling Product Innovation on Fireworks
JSON and grammar mode represent an important improvement in LLM usability by enabling controllable output with guaranteed accuracy. Spend less time fiddling with your system prompt wordings or few-shot examples! JSON mode and grammar mode make it easier than ever to build complex systems where LLMs programmatically call functions or pipe output to other systems.
Fireworks is committed to providing the best platform for Generative AI product innovation and the best experience for structured output. Compared to other providers, we’re excited to offer JSON mode with blazing fast speed for low-latency cases. In our benchmarks, our JSON mode provided 120 tokens/sec while the average “JSON mode” from competing platforms generated 30 tokens/sec.
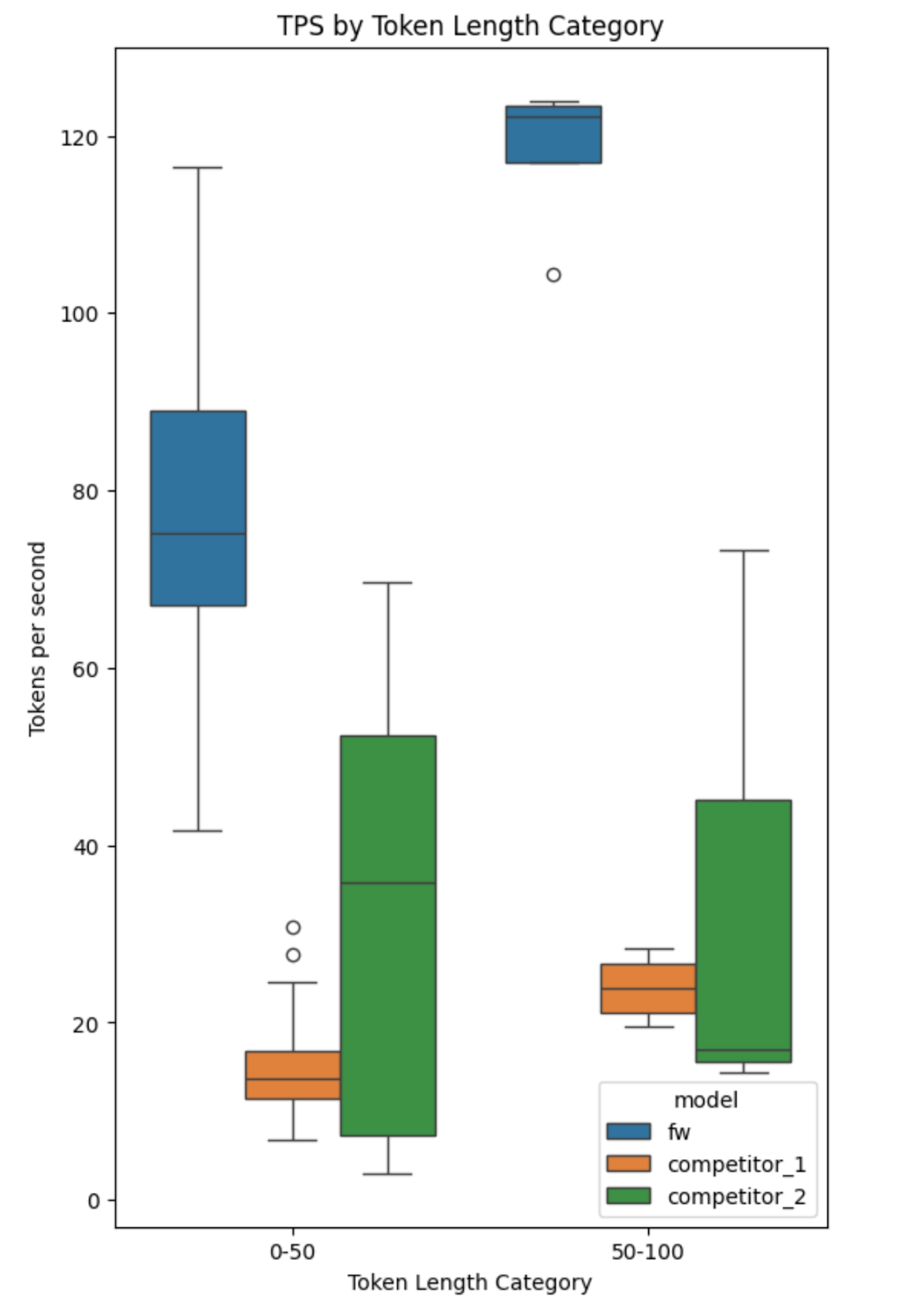
Beyond JSON mode, we’re the only inference platform that we’re aware of with grammar mode. We’ve also just released our own “FireFunction” function calling models (see docs) for more complex use cases that require intent detection in addition to structured output. The model excels at tasks like making decisions between multiple structured schemas or deciding how to fill more complex schemas.
Get started today with our docs on JSON mode and grammar mode to get 100% syntactically correct output and dramatically improved end-to-end accuracy for your application! Visit the Fireworks models page to get started with any of our Fireworks-hosted models - served at blazing fast speeds and an OpenAI-compatible API. Use JSON mode and grammar mode with any of these models to bring unparalleled responsiveness and quality to your users.
We’d love to hear what you think! Please join the function calling channel on our Discord community to discuss our structured output offerings with the team. Happy building!