
20x faster Whisper than OpenAI - Fireworks audio transcribes 1 hour in 4 seconds
By |11/3/2024
Today, Fireworks is thrilled to announce the beta release of our speech-to-text APIs that support the Whisper v3-large models. Use it free for the next 2 weeks! Key features include:
- Speed: Transcribe 1 hour of audio in less than 4 seconds
- Feature completeness: Use built-in features like translation, transcription alignment, voice activity detection and audio preprocessing
Why it matters: Audio transcription and translation use cases are exploding in importance. Fireworks audio excels at real-world, production use cases. Fireworks’ speed enables unmatched user experiences and our complete feature slate makes it easy to get the best quality and production-readiness.
The compound AI audio opportunity
At Fireworks, we believe we’re entering a new era of multi-modal, audio-driven AI. Products like NotebookLM (and open variants built on Fireworks) demonstrate how audio and text AI can combine to create magical user experiences. Fireworks customers like Cresta are innovating to create audio-first assistants while other customers create audio-based language learning assistants, tutors or call summarizers.
These combined audio and text experiences are a marquee example of the power of compound AI. Compound AI describes AI systems created with multiple components like models, API calls, data stores and/or retrievers. These systems stand in contrast to relying on a single call to one large, foundational model.
Why speed matters
Low-latency is critical for engaging audio experiences. For example users need to wait multiple seconds for an audio agent or minutes to process an audio file, this quickly breaks product immersion and causes user frustration. Today, users expect generative AI to respond immediately, not in minutes or hours.
Introducing Fireworks Audio API
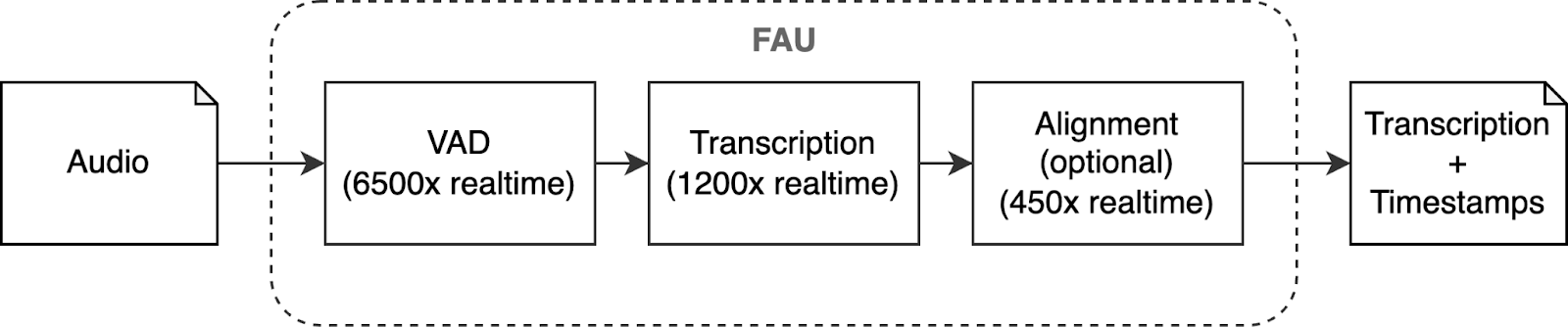
Fireworks offers 2 main audio API options:
- Transcribe audio (async) - Take in an audio file and get transcribed text in bulk with lightning fast speeds
- Text-audio transcription alignment - Provide an audio file (and optionally provide a transcript) and receive transcribed text with start and end timestamps for every word and sentence.
Besides simply providing these models, Fireworks provides tooling for improving audio quality and usability for your application. Across the 3 APIs, we support the following options:
- (1) Translate audio - Transcribe and translate audio into dozens of supported languages
- (2) Preprocessing audio filter presets - To handle reduced-quality audio with better accuracy
- (3) Voice activity detection (VAD) - Get faster and more efficient transcription by removing silent intervals in your audio by using a Fireworks-optimized model (based on Silero VAD)
These APIs come in 2 deployment methods:
- Serverless Audio APIs: Use audio on Fireworks-configured GPUs and pay per audio minute to get started instantly. Please note that the serverless APIs will not reach the same speeds as dedicated deployments during this beta period. Both whisper-v3-large and whisper-v3-large-turbo are offered serverless.
- Dedicated Audio Endpoints - Deploy on private, dedicated hardware for ultimate scalability and production-readiness. Hardware capacity is measured in a curated, audio-optimized grouping of hardware that we’ve termed a Fireworks Audio Unit (FAU). Contact us to get a dedicated endpoint.
Providing 20x+ speed and 10x cost improvements
The fastest Whisper
We’ve made the fastest Whisper model as measured by Artificial Analysis. Our speed improvements come from serving stack innovations from years of experience building Pytorch.

The asynchronous Speech-to-text API can transcribe or translate 1 hour of audio in 4 seconds (or 900x real-time). Results on a dedicated endpoints result in:
- Latency 2-400x lower than from other Whisper providers (including 23x compared to OpenAI)
- Cost of 10x lower than OpenAI Whisper and 2-10x lower than other providers of whisper-v3-large
We also observe large speed wins with our real-time speech API. Audio chunks are transcribed with ~200ms latency resulting in human-feeling experiences.
Async Transcription Measurements
| Model | Price ($ per audio min) | Latency (Seconds per 1 hour audio) | Throughput (audio min/min) |
|---|---|---|---|
| [Dedicated] Whisper-v3-large (beam size 1) | Custom | 4.5 sec | 2000 |
| [Dedicated] Whisper-v3-large (beam size 5) | Custom | 9 sec | 400 |
| [Dedicated] Whisper-v3-large-turbo (beam size 1) | Custom | 3 sec | 3500 |
| [Dedicated] Whisper-v3-large-turbo (beam size 5) | Custom | 6 sec | 700 |
| [Serverless] Whisper-v3-large (beam size 5) | $0.0015 | 11 sec | Variable |
| [Serverless] Whisper-v3-large-turbo (beam size 5) | $0.0009 | 7 sec | Variable |
| OpenAI whisper (v2) | $0.006 | 105 sec | Variable |
Tested using FLAC encoded mono 16 000 sample rate on a dedicated endpoint with 1 FAU;
Maintaining quality
While making speed optimizations, we ensured that quality was not compromised. Word Error Rate (WER) metric is commonly used today to evaluate speech recognition quality. We report WER of 2.00% for greedy inference for whisper-v3-large on the Librispeech Clean dataset (see leaderboard), matching the original open-sourced whisper-v3-large.
Providing a complete transcription toolbox
Many transcription use cases need more than just text transcriptions: they require information on when words, sentences and silent intervals occurred. For example:
- Generating video captions: Require a text to be timed with audio
- Data for training speech recognition models: Requires detailing how spoken words correspond with text transcripts
- Editing audio files/podcasts: Requires knowing when individual words or silent periods start
Fireworks Audio APIs supports text alignment out-of-the-box, providing start and end timestamps for each word and sentence. We support 3 aligner models: Gentle (the industry’s leading text aligner), mms_fa and tdnn_ffn. See below for an example of aligner output, generated from this example notebook.
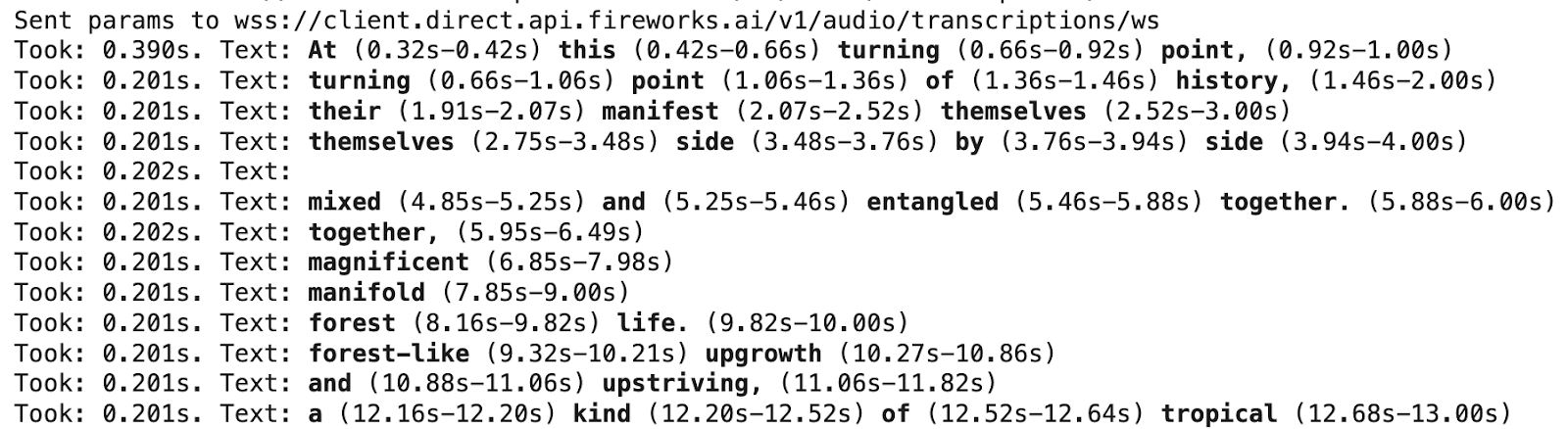
To provide the fastest, most efficient transcription, Fireworks innovated on audio deployment methodology by offering Gentle on GPU compute, instead of CPU compute. This optimization enables up to 10x more efficient compute for Gentle-based alignment, with no accuracy impact. Fireworks can align 1 hour of audio in 10 seconds.
Beyond offering this aligner, we also offer other transcription optionizations and tools:
- Audio transcoding - Our pipeline will accept audio in common formats such as mp3, m4a, wav, and flac. It will first transcode the input audio encoded at 7200x of real time, taking only 0.5 second for 1 hour of compressed AAC LC (widely used audio codec)
- Audio preprocessing - After transcoding, the pipeline will apply the user-selected optional audio filters to handle non-studio-quality audio (from dynamic, soft_dynamic, and bass_dynamic) to boost transcription quality
- Voice Activity Detection (VAD) - Before handing the workload to the transcription model, the pipeline will use Voice Activity Detection (VAD) via Fireworks-optimized version of open-source Silero VAD to remove the silent intervals to reduce waste of compute at the speed of up to 8000x of real time.
Start using Fireworks Audio APIs
Get started with the serverless Fireworks audio endpoints today. These endpoints are offered free for the next two weeks. Users will be notified before pricing is enabled or if they run into rate limits.
Try the endpoints directly in code or directly try them in our UI playground. Our playground provides a UI to directly record or upload audio and run it through Fireworks’ audio APIs. Get code to recreate your UI call in one click.

For inspiration, try out this cookbook. For the best performance, contact us at inquiries@fireworks.ai for a dedicated endpoint
Innovate on Fireworks

Audio adds to a growing list of modalities on Fireworks, including text, image, vision understanding and embeddings models. Fireworks makes it easy to build compound AI systems, by providing one place for:
- Inference: Run all types of models and components fast and cost-effectively
- Models and modalities: Get all the models you need for your system in one place, across modalities like text, audio, image and vision understanding
- Adaptability: Tune and optimize models for quality and speed to suit your use case
- Compound AI: Coordinate and run components together by using Fireworks frameworks and tools like function calling and JSON mode
Keep in touch with us on Discord or Twitter. Stay tuned for more updates coming soon about Fireworks and audio!