
DeepSeek R1: All you need to know 🐳
By |1/24/2025
What we’ll cover this this blog
- Brief overview of DeepSeek R1
- Key features and capabilities
- Open-source and accessibility
- Model architecture
- Reinforcement learning training
- Variants and distilled models
- Use cases and applications
- Migrating from proprietary models to open-source
I. Brief overview of DeepSeek R1
LLM research space is undergoing rapid evolution, with each new model pushing the boundaries of what machines can accomplish. DeepSeek R1, released on January 20, 2025, by DeepSeek, represents a significant leap in the realm of open-source reasoning models. With capabilities rivaling top proprietary solutions, DeepSeek R1 aims to make advanced reasoning, problem-solving, and real-time decision-making more accessible to researchers and developers across the globe.
DeepSeek R1 is an open-source AI model that stands out for its reasoning-centric design. While many large language models excel at language understanding, DeepSeek R1 goes a step further by focusing on logical inference, mathematical problem-solving, and reflection capabilities—features that are often guarded behind closed-source APIs.
Reasoning models are crucial for tasks where simple pattern recognition is insufficient. From complex mathematical proofs to high-stakes decision-making systems, the ability to reason about problems step-by-step can vastly improve accuracy, reliability, and transparency in AI-driven applications.
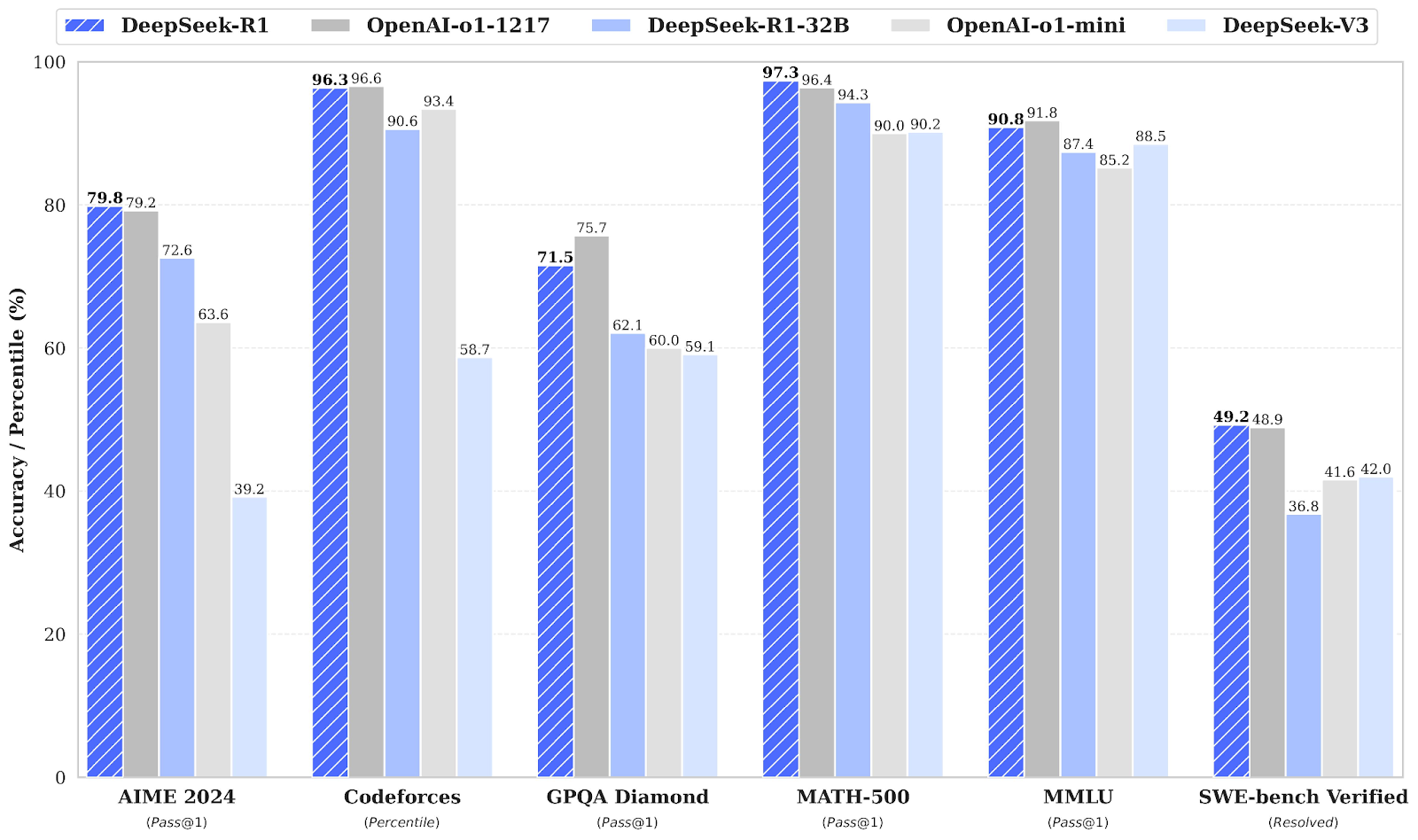
2. Key features and capabilities
DeepSeek R1 excels at tasks demanding logical inference, chain-of-thought reasoning, and real-time decision-making. Whether it’s solving high-level mathematics, generating sophisticated code, or breaking down complex scientific questions, DeepSeek R1’s RL-based architecture allows it to self-discover and refine reasoning strategies over time.
Various independent benchmarks highlight the model’s strong performance:
- Mathematical Competitions: Achieves ~79.8% pass@1 on the American Invitational Mathematics Examination (AIME) and ~97.3% pass@1 on the MATH-500 dataset.
- Coding: Surpasses previous open-source efforts in code generation and debugging tasks, reaching a 2,029 Elo rating on Codeforces-like challenge scenarios.
- Reasoning Tasks: Shows performance on par with OpenAI’s o1 model across complex reasoning benchmarks.
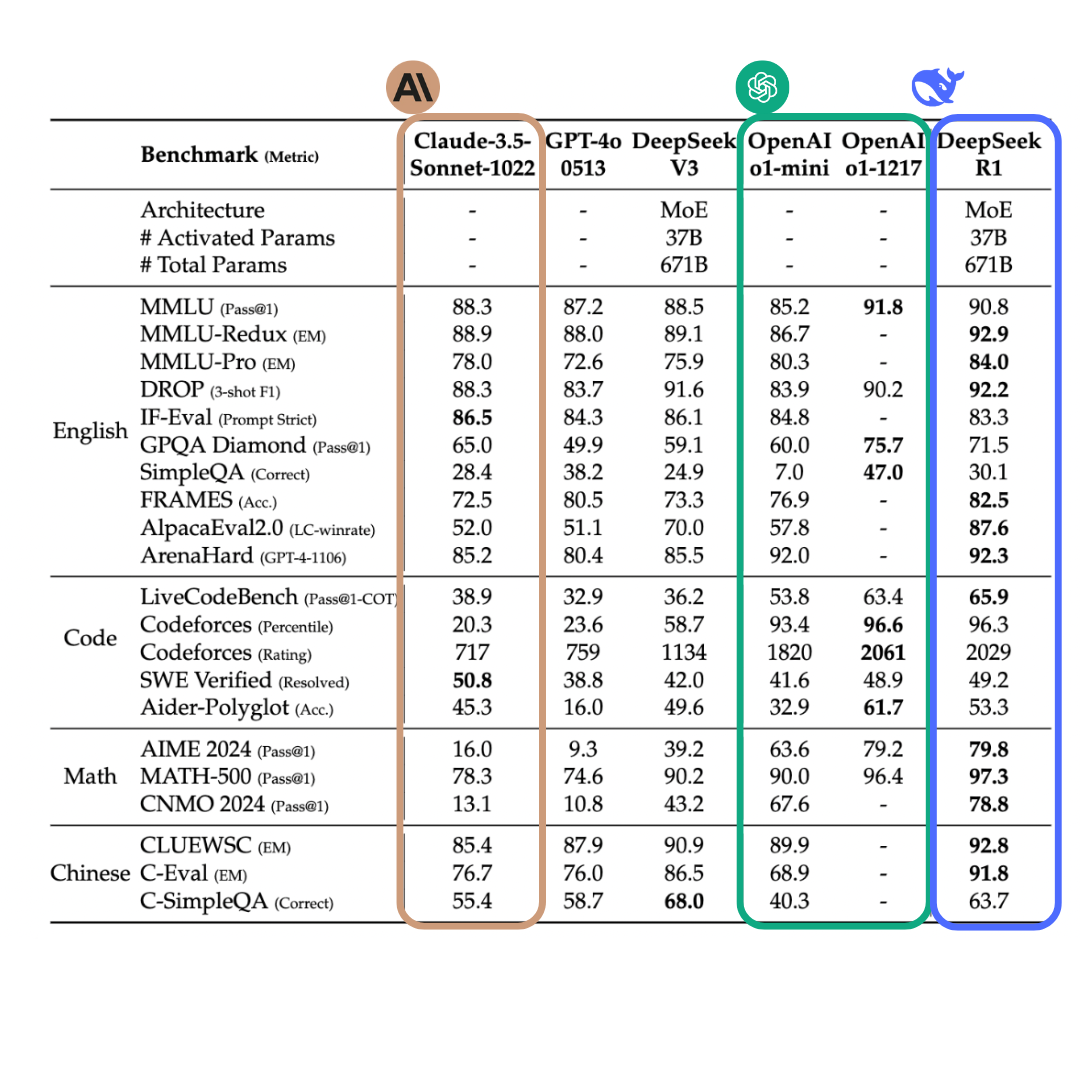
Despite having a massive 671 billion parameters in total, only 37 billion are activated per forward pass, making DeepSeek R1 more resource-efficient than most similarly large models. The Mixture of Experts (MoE) approach ensures scalability without proportional increases in computational cost.
3. Open-source and accessibility
DeepSeek R1 is distributed under the permissive MIT license, granting researchers and developers the freedom to inspect and modify the code, use the model for commercial purposes, and integrate it into proprietary systems
One of the most striking benefits is its affordability. Operational expenses are estimated at only around 15%-50% based on the input/output token size (likely closer to 15% since output token counts could dominate for reasoning models) of what users typically spend on OpenAI’s o1 model**.** Cost of running DeepSeek R1 on Fireworks AI is $8/ 1 M token (both input & output), whereas, running OpenAI o1 model costs $15/ 1M input tokens and $60/ 1M output tokens.. This cost efficiency democratizes access to high-level AI capabilities, making it feasible for startups and academic labs with limited funding to leverage advanced reasoning.
Because it is fully open-source, the broader AI community can examine how the RL-based approach is implemented, contribute enhancements or specialized modules, and extend it to unique use cases with fewer licensing concerns.
4. Model architecture
DeepSeek R1 employs a Mixture of Experts (MoE) framework:
- 671 Billion Parameters: Encompasses multiple expert networks.
- 37 Billion Activated per Forward Pass: Keeps computational overhead in check by routing queries to the most relevant expert “clusters.”
This structure is built upon the DeepSeek-V3 base model, which laid the groundwork for multi-domain language understanding. MoE allows the model to specialize in different problem domains while maintaining overall efficiency.
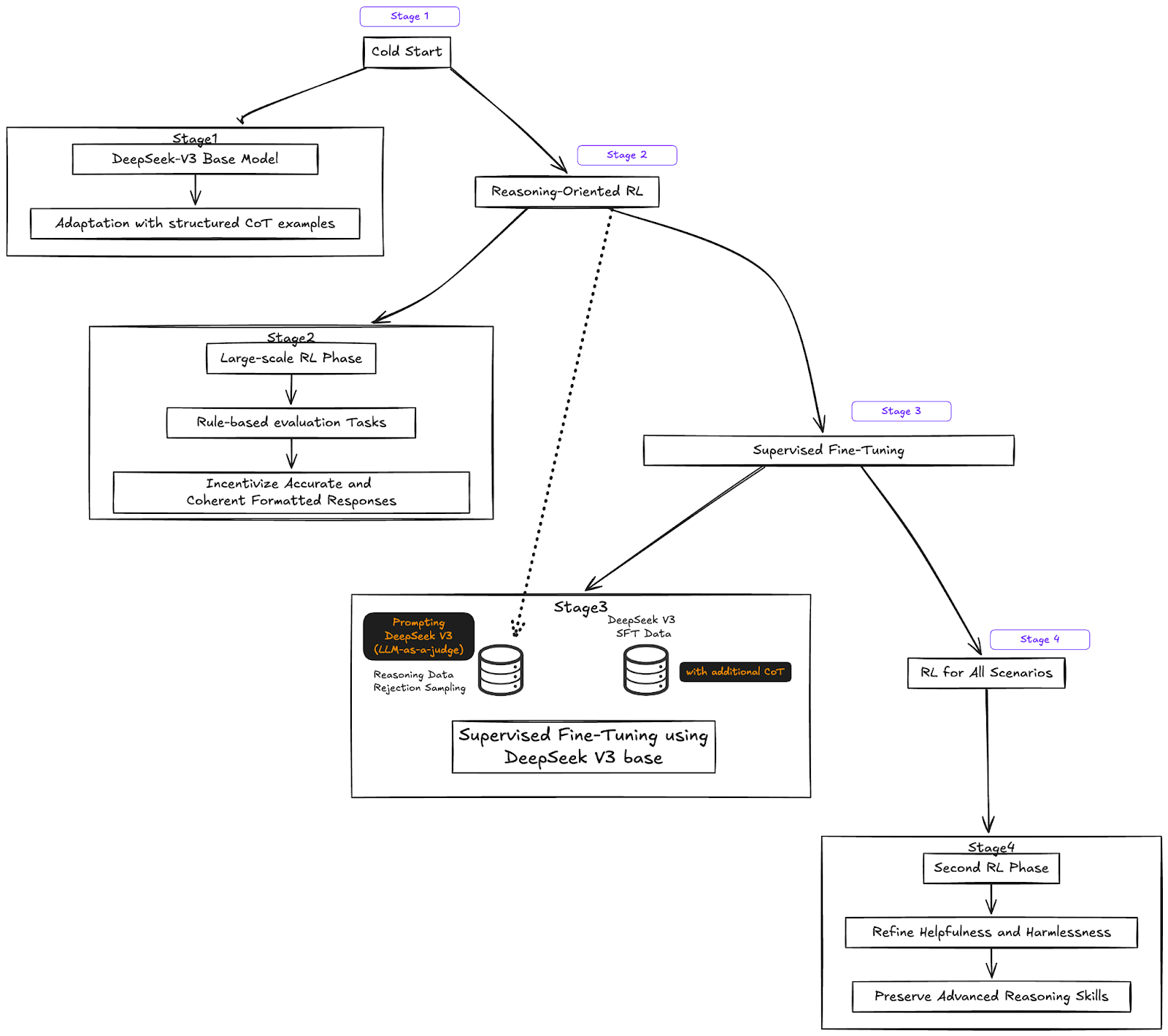
5. Reinforcement learning training
DeepSeek-R1 employs a distinctive training methodology that emphasizes reinforcement learning (RL) to enhance its reasoning capabilities. Initially, the model undergoes supervised fine-tuning (SFT) using a curated dataset of long chain-of-thought examples. Following this, RL is applied to further develop its reasoning skills. This approach encourages the autonomous emergence of behaviors such as chain-of-thought reasoning, self-verification, and error correction. By integrating SFT with RL, DeepSeek-R1 effectively fosters advanced reasoning capabilities.
- Stage 1 - Cold Start: The DeepSeek-V3-base model is adapted using thousands of structured Chain-of-Thought (CoT) examples.
- Stage 2 - Reasoning-Oriented RL: A large-scale RL phase focuses on rule-based evaluation tasks, incentivizing accurate and formatted-coherent responses.
- Stage 3 - Supervised Fine-Tuning: Reasoning SFT data was synthesized with Rejection Sampling on generations from Stage 2 model, where DeepSeek V3 was used as a judge. Non-reasoning data is a subset of DeepSeek V3 SFT data augmented with CoT (also generated with DeepSeek V3). Combine both data and fine tune DeepSeek-V3-base.
- Stage 4 - RL for All Scenarios: A second RL phase refines the model’s helpfulness and harmlessness while preserving advanced reasoning skills.
DeepSeek R1’s RL-first approach:
- Reduces reliance on large-scale human-annotated data
- Uncovers emergent behaviors like reflection and self-correction sooner
- Potentially lowers total training costs by streamlining data collection
6. Variants and distilled models
- DeepSeek R1-Zero
This precursor model was trained using large-scale reinforcement learning without supervised fine-tuning. It laid the groundwork for the more refined DeepSeek R1 by exploring the viability of pure RL approaches in generating coherent reasoning steps.
- Distilled Versions (1.5B to 70B parameter models)
For developers with limited hardware, DeepSeek offers smaller “distilled” variants of R1 with base models as Qwen and Llama models:
- 1.5B Parameter Model: Runs efficiently on high-end consumer GPUs, suitable for prototyping or resource-limited environments.
- 70B Parameter Model: Balances performance and computational cost, still competitive on many tasks.
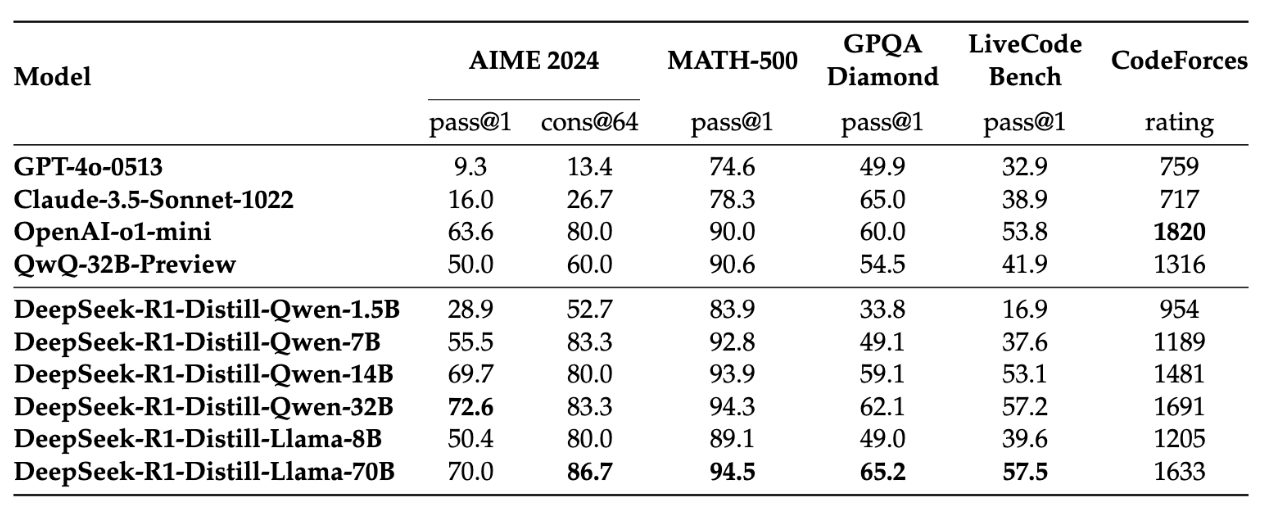
While these distilled models generally yield slightly lower performance metrics than the full 671B-parameter version, they remain highly capable—often outperforming other open-source models in the same parameter range.
7. Use cases and applications
DeepSeek R1’s advanced reasoning and cost-effectiveness open doors to a wide range of applications that includes the following. These use-cases are industry agnostic:

8. Migrating from proprietary models to open-source
Increasingly, organizations are looking to move from closed-source LLMs, such as Anthropic’s Claude Sonnet or OpenAI’s GPT-4/o1, to open-source alternatives. DeepSeek R1 (and its distilled variants) offer comparable or superior quality in many reasoning, coding, and math benchmarks. Beyond performance, open-source models provide greater control, speed, and cost benefits.
Anthropic is known to impose rate limits on code generation and advanced reasoning tasks, sometimes constraining enterprise use cases. DeepSeek R1’s open license and high-end reasoning performance make it an appealing option for those seeking to reduce dependency on proprietary models.
DeepSeek R1 will be faster and cheaper than Sonnet once Fireworks optimizations are complete and it frees you from rate limits and proprietary constraints.
Note__: At Fireworks, we are further optimizing DeepSeek R1 to deliver a faster and cost efficient alternative to Sonnet or OpenAI o1.
Potential Benefits of Migration (Speed, Cost, Control)
- Production Deployment of large DeepSeek models — with additional optimizations underway
- Distillation to smaller models — significantly lowering latency and cost but requiring a design partnership to preserve essential performance
- Full Transparency on data used for fine-tuning (thanks to the MIT license)
Fireworks AI is one of the very few inference platforms that is hosting DeepSeek models. Fireworks is also the best platform to assess these open models and to move production AI workloads from closed-source models such as OpenAI, Anthropic, and Gemini to a more transparent, controllable, and cost-effective environment.
For those ready to explore open-source alternatives to GPT-4, Claude Sonnet, or o1, DeepSeek R1 (and its distilled variants) represent a powerful, transparent, and cost-effective choice. Fireworks stands ready to help you evaluate these capabilities and migrate production workloads—all while enjoying the flexibility and openness that proprietary solutions can’t match.
Try it out today 🐳
You can try DeepSeek R1 and DeepSeek V3 models on Fireworks AI playground:
As well as a number of R1 distilled models we now host:

Why Fireworks AI
Fireworks AI is an enterprise scale LLM inference engine. Today, several AI-enabled developer experiences built on the Fireworks Inference platform are serving millions of developers.
Fireworks lightning fast serving stack enables enterprises to build mission critical Generative AI Applications that are super low latency. With methods like prompt caching, speculative API, we guarantee high throughput performance with low total cost of ownership (TCO) in addition to bringing best of the open-source LLMs on the same day of the launch.
If you have more questions, join our community and tag a Fireworks AI team member or drop a note to discuss building with LLMs from prototype to production.