FireAttention — Serving Open Source Models 4x faster than vLLM by quantizing with ~no tradeoffs
By Fireworks.ai|1/8/2024
Intro
Mixtral has recently made waves in the AI community as the first OSS model trained on trillions of tokens to support 'mixture of experts' (MoE), which has promising features to speed up both training and inference.
Fireworks AI was the first platform to host Mixtral, even before its public release.
While the initial hype has calmed down, we took time to answer the following question:
Can we develop a dramatically more efficient serving for MoE models with a negligible quality impact?
To answer this question, we've introduced Fireworks LLM serving stack, with FP16 and FP8-based FireAttention being the core part. It delivers 4x speedup, compared to other OSS alternatives. We will present a quality and performance study based on the Mixtral model.
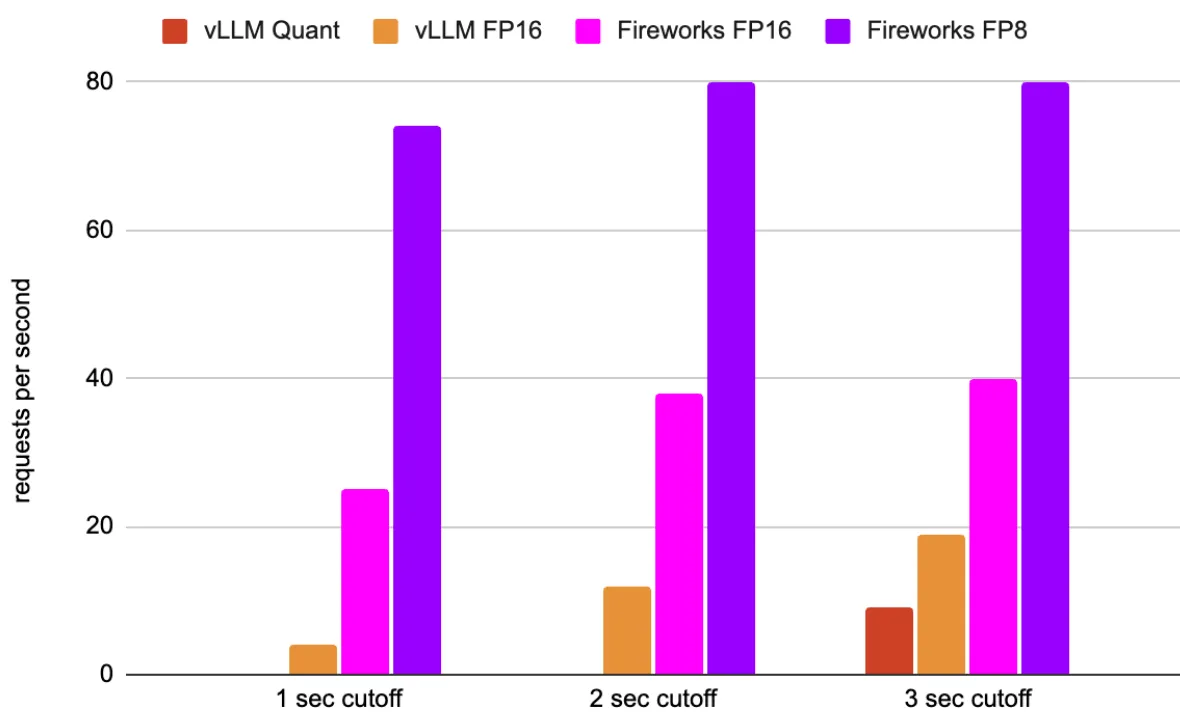
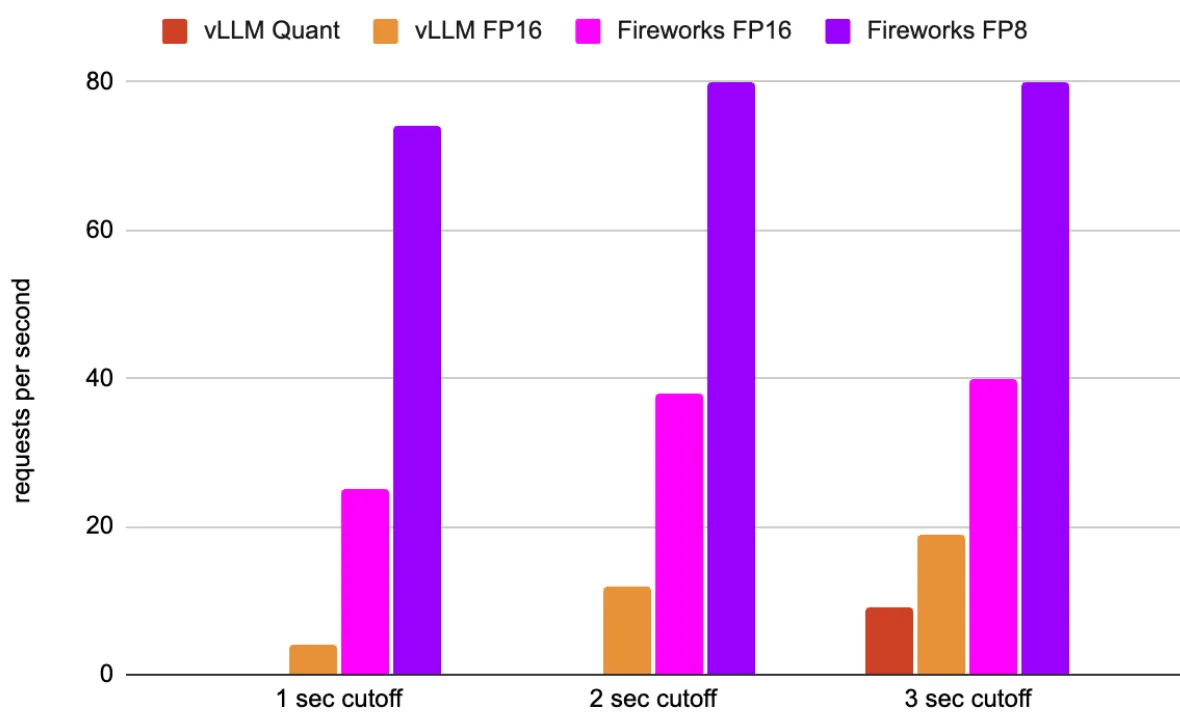
Achieved requests per second (higher the better) for Mixtral on 8 H100 GPUs at different request latency cutoffs (see Performance Analysis below for details)
Setup
As there is no 'one size fits all' in the LLM performance world, in this post, we want to focus on one of the most typical use cases: prompt length = 1K , number of generated tokens = 50. This setup covers the long prompt, short generation use case. We argue that short prompts and/or long generations call for quite different optimization strategies, which we will cover in other posts.
When measuring model quality, we will focus on language understanding. We'll use the MMLU metric, which has enough test dataset examples (over 14K) and on which the Mixtral model performs quite well (70.6% accuracy), but not too well. This allows us to make any quantization error quite visible in the resulting accuracy numbers.
Production use cases typically have 'best throughput for a given latency budget' requirement. Thus we are going to use two metrics: one is token generation latency for a given number of requests/second (RPS) and the second one is a total request latency for a given RPS. Different service setups can shift latencies from prefill to generation and vice versa. Measuring these two metrics allows us to clearly see the overall picture.
FireAttention
FireAttention is a custom CUDA kernel, optimized for Multi-Query Attention models (Mixtral is one of them). It is also specifically optimized for FP16 and FP8 support in new hardware, notably H100. It runs close to the hardware memory bandwidth limit during generation for various batch sizes and sequence lengths.
FireAttention is integrated into Fireworks proprietary LLM serving stack, which consists of CUDA kernels, optimized for both FP16 and FP8.
Quality Analysis
Running a model in half-precision leaves a lot of performance on the table, as modern GPUs have 2x FLOPs for INT8/FP8 types as compared to half/bfloat16 types. Also as memory bandwidth is the bottleneck during generation, we should try to shrink both weights and key/value caches.
Many integer quantization methods for LLMs emerged. We've experimented with a few following Huggingface's recommendation. We also evaluated our FP8 implementation.
Our FP8 implementation runs 3 experts per each token (as opposed to the default 2). See this post about concrete reasoning details.
We've measured the MMLU metric using a standard 5-shot template against the base Mixtral model.
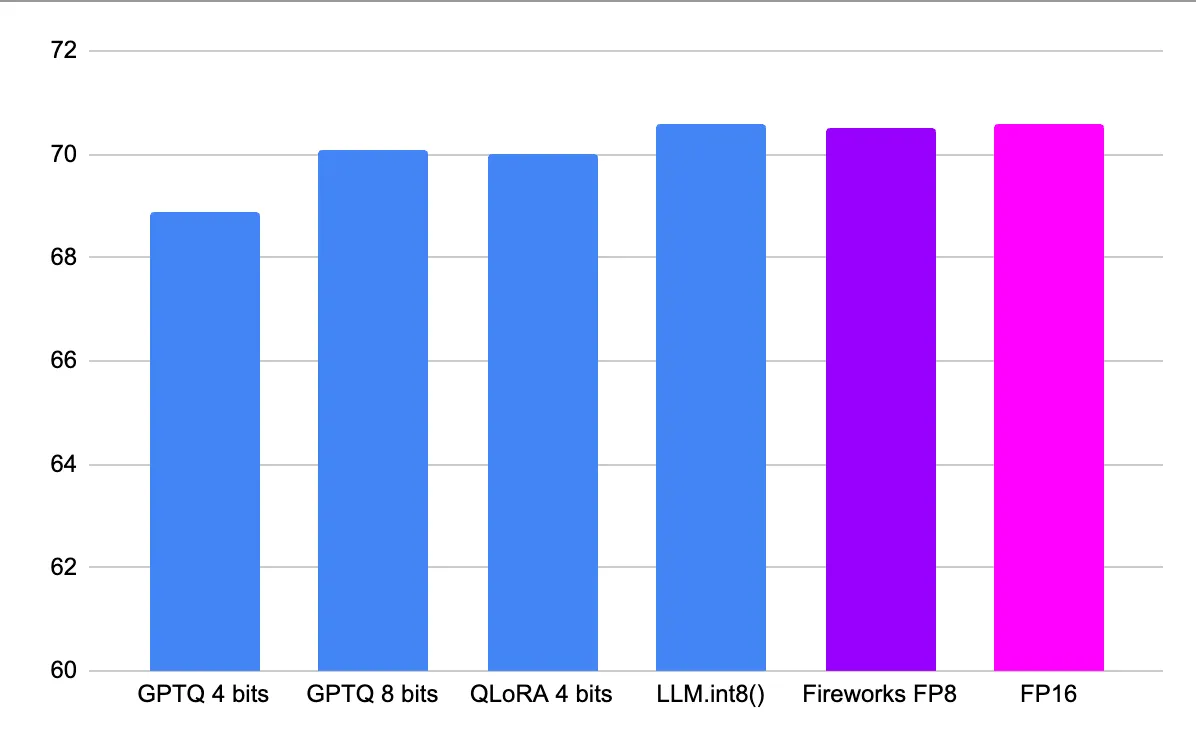
- GPTQ models were obtained from GPTQ 8 bits and GPTQ 4 bits checkpoints.
- LLM.int8() was obtained from the original model by passing load_in_8bit=True,dtype=float16
- QLoRA 4 bit version was obtained by passing load_in_4bit=True,bnb_4bit_compute_dtype=float16 to the model constructor.
While LLM.int8() (and to some extent QLoRA) match the original model's quality, none of the integer quantization methods above provide any inference speed-ups, especially when running with batch sizes more than 1. Some good analysis is done here.
Other methods like SmoothQuant and AWQ try to improve a model's performance, but still fall short, especially during generation. The fundamental issue of integer quantization still remains. And the issue is that LLM activations do not have uniform distribution, thus posing a challenge to integer methods.
FP8 on the other hand, provides a very promising opportunity as it's more flexible to accommodate for non-uniform distributions leveraging hardware support.
Superiority of floating-point quantization for LLMs was covered in numerous papers. Some quotes:
ZeroQuant-FP (Wu, X. et al. 2023) Notably, FP8 activation exceeds INT8, especially in larger models. Moreover, FP8 and FP4 weight quantization are either competitive with or surpass their INT equivalents.
Which GPU(s) to Get for Deep Learning (Dettmers T. 2023) We can see that bit-by-bit, the FP4 data type preserve more information than Int4 data type and thus improves the mean LLM zeroshot accuracy across 4 tasks.
FP8 Quantization: The Power of the Exponent (Kuzmin A, et al. 2022) Our chief conclusion is that when doing post-training quantization for a wide range of networks, the FP8 format is better than INT8 in terms of accuracy, and the choice of the number of exponent bits is driven by the severity of outliers in the network.
Still, practical support for FP8 remains quite scarce in OSS LLM serving implementations.
We also ran other major benchmarks comparing FP16 and FP8. Here's the complete list:
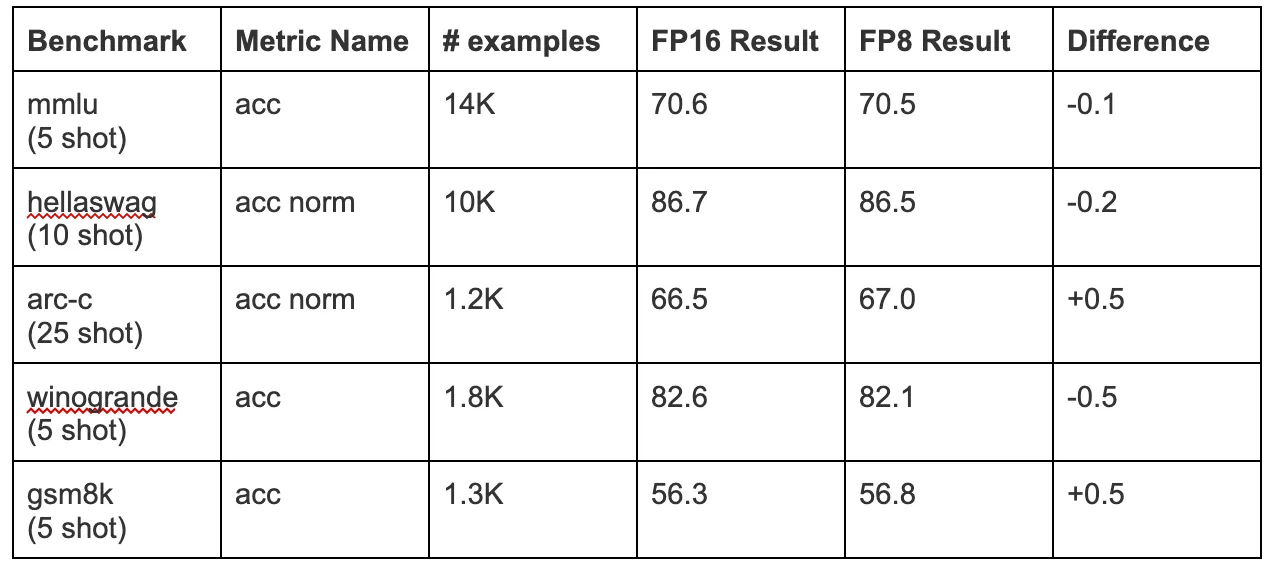
Because of a small number of examples, arc-c/winogrande/gsm8k benchmark results differences are only meaningful at ~1%.
Based on these results we can make a conclusion that Fireworks FP8 implementation has a very small base model quality impact, which will be negligible in concrete fine-tuned versions.
Performance Analysis
We could not come by a working implementation of FP8 in Mixtral in OSS (TensorRT-LLM supports Mixtral and separately FP8 on selected few models, but FP8 doesn't work with Mixtral currently). Instead we are going to compare our FP16 with our FP8 implementation and will also cross-check with a very well-known OSS alternative vLLM for FP16 numbers.
We also ran vLLM in GPTQ Int8 mode. Unfortunately, currently vLLM Int8 quantization doesn't work in multi-gpu mode, so we used a single GPU only. Although latencies should improve when running in multi-gpu mode, we don't expect it to meaningfully beat vLLM FP16 numbers.
We also ran vLLM in AWQ Int4 mode. Unfortunately, total request latencies even for a single concurrent request were above the 3 sec cut-off.
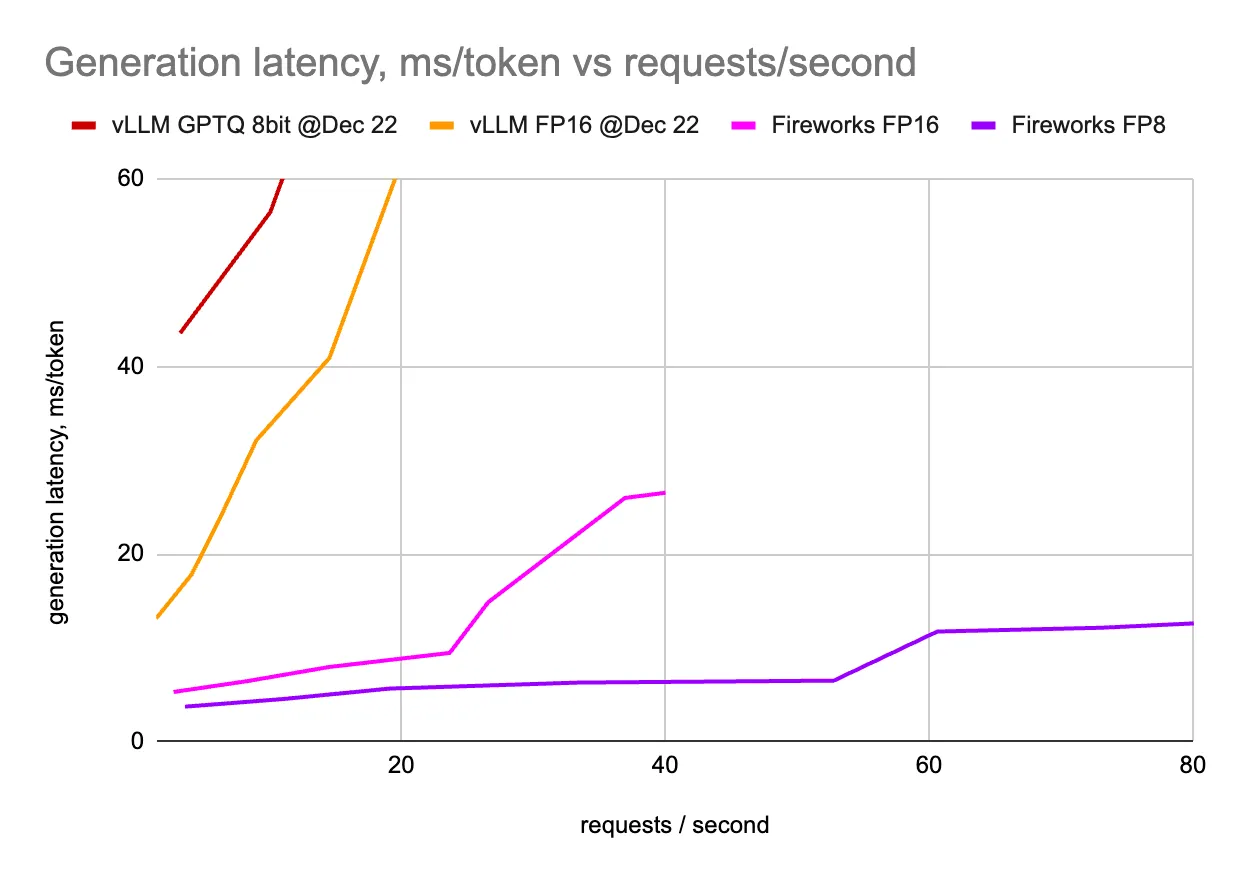
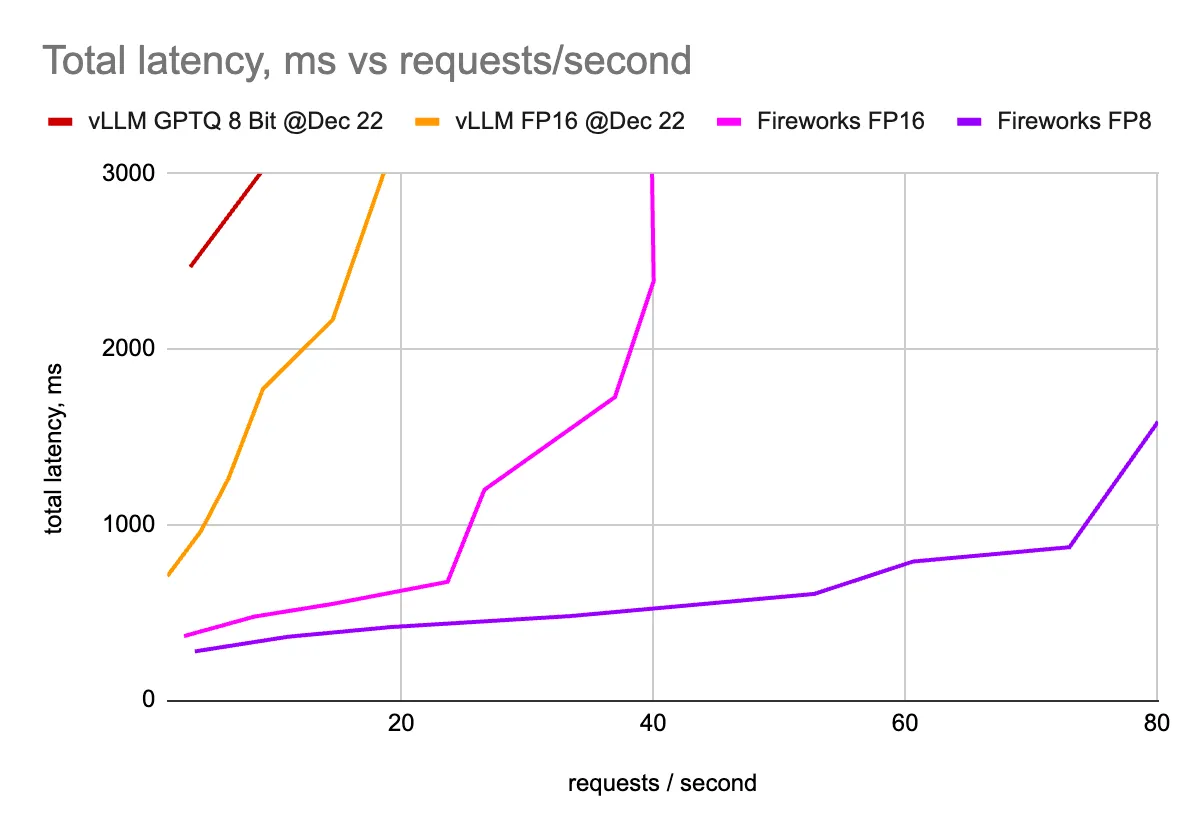
We've deployed the Mixtral model on 8 H100 GPUs and measured token generation latencies as well as total request latencies while varying the number of concurrent requests.
We've deployed vLLM in many configurations: 2, 4, and 8 GPUs (over tensor parallelism). We've multiplied the resulting QPS by 4, 2, and 1, respectively. The graphs display the best latency values for a given QPS.
We've deployed Fireworks LLM service using many different configurations, and similar to vLLM, we've shown numbers from the winning configuration only.
Conclusions
Several key takeaways:
- Fireworks FP16 Mixtral model implementation is superior to the one from vLLM
- Fireworks FP8 implementation significantly improves over the already quite efficient Fireworks FP16 implementation.
- Because FP8 shrinks model size 2x, it allows for more efficient deployment. Combined with memory bandwidth and FLOPs speed-ups this results in 2x improvement of the effective requests/second.
- There is no 'one size fits all' regarding LLM performance. Different configurations of both vLLM and Fireworks LLM service show their strengths in different setups.
Overall, Fireworks FireAttention FP8 implementation provides the best tradeoff for LLM serving on the accuracy/performance trade-off curve.
Check out Fireworks GenAI Platform if you want to get SOTA LLM performance including FP8-based FireAttention, accessible via our API endpoints. Contact us for enterprise plan and deployment with the best speed and cost to serve catered for your workload.
We are hiring!
If you are interested in deep system work and driving foundation model optimization innovation, please send your resume to careers@fireworks.ai. We are hiring system engineers, performance engineers and AI researchers. Check out all openings on our Careers page.