
FireAttention V2: 12x faster to make Long Contexts practical for Online Inference
By |6/20/2024
Importance and Challenges of Long Context
Long contexts have many practical applications, especially in RAG, code completion, classification, etc. Yet, long context has been challenging, especially in online applications, both from model quality and inference speed standpoints.
The goal of this post is to push the boundaries of both quality and inference speeds to make long context use cases practical. We will focus on 8K-32K contexts as we are yet to see an OSS model, which works well on long context benchmarks beyond a simple needle search for contexts over 32K.
This post complements our previous post in the FireAttention series.
FireAttention V2
Since the launch of FireAttention, Fireworks team was working on pushing the boundaries of long context LLM performance. The following charts of throughput and latency improvements are a result of this work:

Notably, the following major improvements were made:
- Hopper support for FP16 prefill kernels and FP8 prefill kernels support.
- Multi-host deployment mode, which is beneficial for use cases with high traffic and balanced prompt/generation ratios. Majority of use cases running on fireworks.ai fall into this category.
Quality Benchmarks
Many new LLMs claim long context support, yet the only widely-accepted benchmark is a ‘needle in a haystack’ .We argue that this benchmark is quite a low bar for an LLM as it doesn’t require any reasoning capabilities. Chunking large contexts and using embedding-based retrieval to reduce context length would be a much more performant option in this case.
Thus we used a quite comprehensive RULER benchmarking library to test more ‘LLM-worthy’ applications. We’ve chosen the following benchmarks: multi-needle, variable tracking and question answering (squad dataset). We think that these benchmarks are the most representative of practical workloads.
We’ve tested a few popular OSS as well as one leading proprietary LLM. For each benchmark we’ve used 100 examples. Results are below.
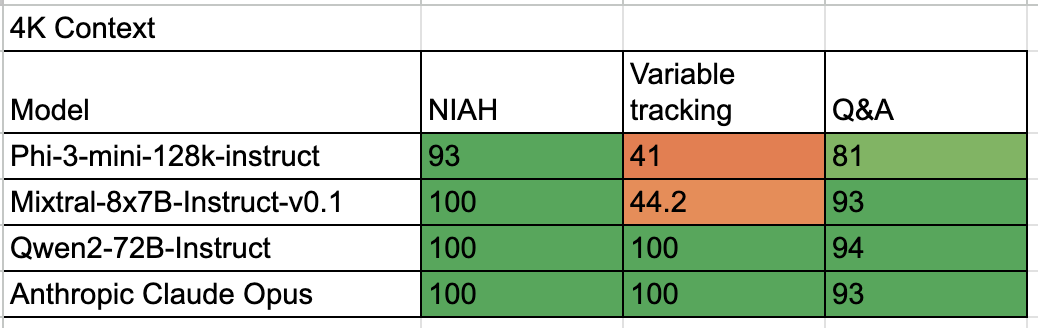
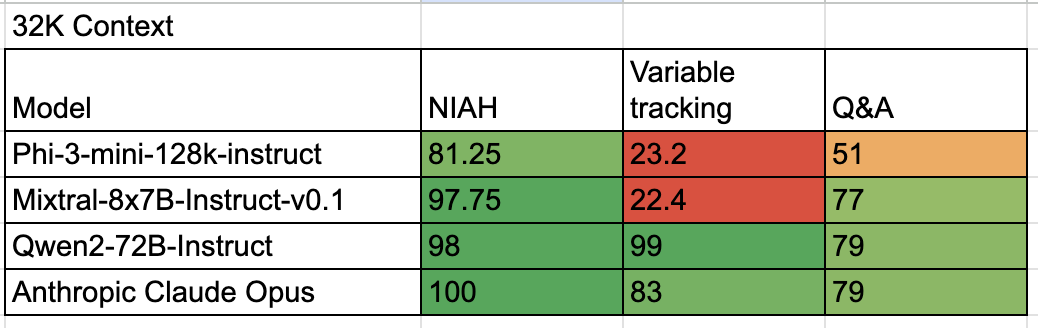
It’s easy to see that from open-source models only Qwen 72B is capable of long context tasks, which go beyond just simple exact retrieval.
We look forward to more open-source LLMs with better long context support!
Performance Benchmarks
We use Qwen2 72B Instruct model to measure long context performance of 32K context in fp16 mode. It is the best model by far for contexts over 8K.
For fp8 mode we use Mixtral 8x7B Instruct model, which also has 32K context support.
We intentionally don’t use any techniques, which condition based on input content, e.g. speculative decoding, prompt caching etc. This makes performance comparisons more fair.
When it comes to performance, there is no ‘one size fits all’. While it’s not possible to cover all cases within this post, we will focus on the most representative workload as we’ve observed on fireworks.ai.
It’s important to measure performance of different context lengths as on short contexts, matrix multiplication dominates while on longer contexts quadratic nature of attention scaling takes over performance profiles.
We measure total latency as depending on server configuration one can optimize for ‘time to first token’ vs ‘generation per token’. This balanced approach allows us to have a quite comprehensive and yet unbiased view.
Measurements were done using our open source benchmarking library and thus can be easily reproduced.
Short-Medium Generations
We use fixed amount of 300 tokens for short-medium generations. We deploy models on 8 H100 GPUs. We measure both latency (vertical axis) and throughput (horizontal axis) differences at 20,000 ms threshold.

Qwen 72B on vLLM 0.5.0 vs Fireworks AI in fp16 on 8 H100 GPUs

Mixtral 8x7B vLLM 0.5.0 vs Fireworks AI in fp8 on 8 H100 GPUs
It’s easy to see that FireAttention dominates vLLM by a wide margin, ~1.7x in fp16 and ~5.6x in fp8 modes for throughput (horizontal axis) and ~3.5x in fp16 and ~12.2 in fp8 for latency (vertical axis). Also domination is similar for shorter (8K) and longer (32K) contexts. This means that FireAttention runtime has both matrix multiplications and attention kernels highly optimized.
Long Generations
We use fixed amount of 1200 tokens for long generations. We deploy models on 16 H100 GPUs. We measure both latency (vertical axis) and throughput (horizontal axis) differences at 60,000 ms threshold.
FireAttention has a mode, when a model can be distributed across multiple hosts. This mode is beneficial for long generations. As vLLM doesn’t support multi-host sharding, we just multiply resulting RPS by 2.

Qwen 72B on vLLM 0.5.0 vs Fireworks AI in fp16 on 16 H100 GPUs

Mixtral 8x7B on vLLM 0.5.0 vs Fireworks AI in fp8 on 16 H100 GPUs
FireAttention multi-host mode allows FireAttention to improve throughput by ~2x more: ~3.7x in fp16 and ~8x in fp8 modes while keeping latency improvement relatively intact: ~4x in fp16 and ~11.3x in fp8 modes.
Try It Now
Qwen 2 72b Instruct , Mixtral 8x7B Instruct as well as numerous other models are available for you to try right now on fireworks.ai and are capable of producing speeds measured in this blog post. It’s also advised to use dedicated deployments to ensure proper performance measurements.
Multi-host mode is only available for enterprise customers. Contact us if your use case fits the long-generation pattern.