
FireOptimizer: Customizing latency and quality for your production inference workload
By |8/22/2024
At Fireworks, we've always believed that off-the-shelf models need to be adapted to meet production-grade performance. Today, we’re excited to introduce FireOptimizer, our adaptation engine designed to customize and enhance AI model performance for your unique use cases and workload. We have launched a new FireOptimizer feature: adaptive speculative execution, which delivers up to 3x latency improvements by tailoring speculative execution to your specific data and needs automatically.
Why It Matters: In today’s world, every millisecond counts. Whether you’re powering real-time customer interactions, processing large-scale data for intelligent search, or using AI to generate code, FireOptimizer simplifies the complex tuning work for optimizing latency and quality, and ensures your models are not just fast, but customized to perform at their best for your unique scenario.
The Benefits:
- Faster Inference: With FireOptimizer’s adaptive speculative execution, production workloads across various models saw up to 3x latency improvements, ensuring applications are always highly responsive.
- Hassle-Free Optimization: FireOptimizer automates the complex optimization process, so you can focus on building your application, while we handle the rest.
Why adaptation matters in AI inference
Many developers are surprised by the extent that results can vary serving the same model on the same hardware. For example, Llama 70B on eight GPUs in a volume-optimized set-up can be 4x cheaper per token than Llama 70B on the same eight GPUS optimized for single request speed. This variation occurs because text distributions and inference requirements may vary dramatically, and a one-size-fits-all approach often fails to deliver optimal performance.
Adaptation is necessary because multiple parts of the serving stack can be adjusted based on specific use cases, enabling organizations to maximize efficiency, quality, and cost-effectiveness. It involves a holistic approach that considers every layer of the deployment stack—hardware, model, and software—to ensure that all components are optimized to work together seamlessly. Adaptation is especially critical when building compound AI systems, where multiple models and processes interact, requiring precise alignment and optimization across the entire system to achieve peak performance.
FireOptimizer allows users to customize their LLM inference set-up for ideal cost, quality and performance. FireOptimizer enables improvements across three key layers of the inference stack:
- Hardware - Which accelerators are you using and how is workload distributed across them? For example, on the same 8 GPUs, you could host 8 separate copies of the model or you host one model copy across multiple GPUs.
- Model - How is a model quantized, tuned, or otherwise customized?
- Software - How are requests processed, cached, and handled? For example, how are prompts vs generations processed?
FireOptimizer employs automatic capabilities to enable adaptation as well as extension to the traditional inference performance improvement approach. Some of these techniques include:
- Adaptive speculative execution
- Adaptive caching
- Customizable quantization
- Adaptive fine-tuning
- Personalized fine-tuning at scale
- Customizable hardware mapping

We have already shared customizable quantization based on quality and latency tradeoff curve before. In this post, we’ll focus specifically on adaptive speculative execution. Stay tuned for more deep dives and future releases.
Adaptive Speculative Execution with FireOptimizer
FireOptimizer employs a new technique called adaptive speculative execution which improves performance by tailoring speculative decoding to your specific workload. For context, speculative decoding is a technique that parallelizes token generation to accelerate inference. Typically, a large language model (LLM) generates tokens one by one, but speculative decoding changes this by using smaller "draft" models to predict possible token sequences in parallel with the main LLM. The main LLM then verifies these predictions—if correct, the draft model's output is used; if incorrect, it’s discarded.

Speculative decoding works based on the two key ideas of :
- Speed of Verification vs. Generation: It’s faster for the LLM to verify a sequence of predicted tokens in parallel than to generate each token individually.
- Hit Rate of the Draft Model: The effectiveness of speculative decoding depends on the draft model’s accuracy, or "hit rate." A high hit rate allows the LLM to incorporate more correct predictions, boosting speed without sacrificing quality.
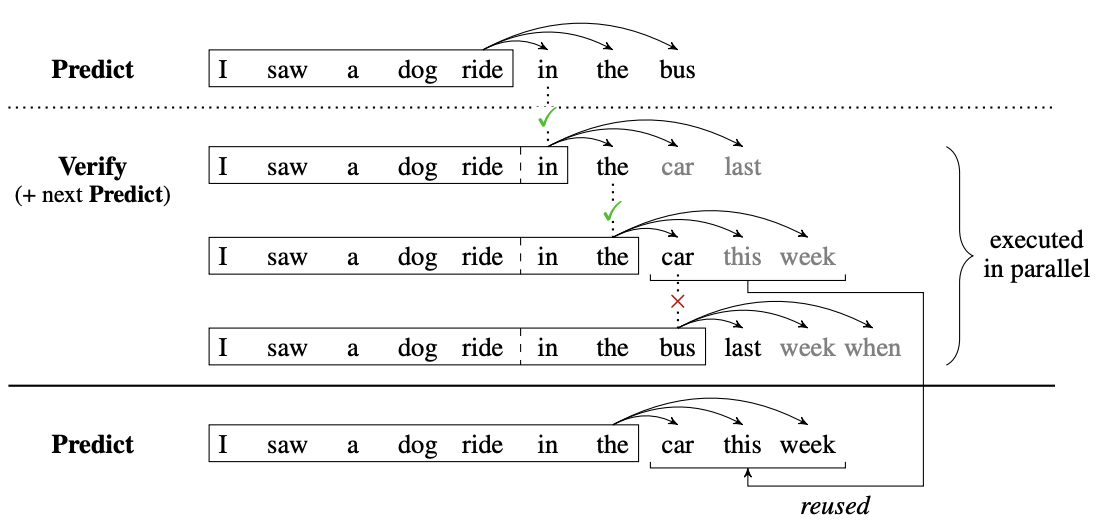
This approach can significantly reduce latency without compromising the response quality, as the LLM ensures the final output remains accurate. However, speculative decoding that uses generic draft models has limitations.
Why Generic Draft Models Fall Short:
In traditional speculative decoding, draft models are typically trained on generic data, like publicly available conversation datasets. While this can work for general use cases, the hit rate—and thus efficiency—declines significantly when applied to more specialized scenarios.
Adaptive Speculative Execution:
FireOptimizer improves upon this technique, unlocking greater potential with ease. FireOptimizer’s adaptive speculative execution is built on two key concepts:
- Profile-driven Customization: FireOptimizer enhances the "hit rate" of the draft model by leveraging the inference workload profile. The higher the hit rate, the greater the latency improvements you’ll experience.
- Automatic Training and Deployment: FireOptimizer handles the training and evaluation of the draft model for you. Simply provide your data, deploy the resulting draft model, and enjoy significant latency reductions without the hassle of manual tuning.
The advantages of this technique are:
- Broad Latency Improvements: Generally across use cases, a specialized draft model, trained on your specific data, achieves a higher hit rate, resulting in more substantial latency improvements.
- Domain-specific Use Cases: The gap between a specialized and a generic draft model is most evident in unique situations, such as coding, where token distributions differ from standard datasets.
- Custom Models: If you’re working with a custom model, a generic draft model might not even be available, making a specialized draft model essential for optimal performance.
By focusing on your specific needs, FireOptimizer ensures that speculative decoding delivers the maximum possible performance improvements.
Let’s take an example. We tested speculative decoding using a generic draft model for a customer with a very specialized use case. The generic draft model’s token distribution was so different from the target use case that speculative decoding actually increased latency by 1.5x**,** given the draft model’s poor hit rate of 29%. When using FireOptimizer, we achieved 76% hit rate with a 2x speed increase. Overall, FireOptimizer adaptive speculative execution can achieve 3x speedup over a generic draft model.
| Hit Rate | Latency Improvement over No Speculative Decoding (%) | |
|---|---|---|
| FireOptimizer | 76% | 2x faster |
| Generic Draft Model | 29% | 1.5x slower |
Automated Improvements with Adaptive Speculative Execution
You might be wondering, “How do I get to a profile-driven customization?” or “How do I measure hit rate and compare the effectiveness of speculative execution?” At Fireworks, we prioritize user experience, so instead of requiring developers to manually train and evaluate draft models for speculative decoding, we’ve built infrastructure that automates the process, ensuring you get the maximum benefit effortlessly.
To use Adaptive Speculative Execution, users simply provide us with data representative of their use case. This can be done in two ways:
- Traced data - Enable some production data to be automatically logged and used for training.
- Provide a sample dataset - Use a dataset representative of your use case to start the customization. This can especially be helpful if you need to anonymize data
Fireworks takes care of the details, so you don’t need to evaluate model hit rates or manage hyperparameters. You’ll simply be presented with an improved draft model that can be deployed for latency improvements.
The ease of deployment ensures performance is always optimal. Like any tuned model, if your production data distribution shifts over time, your model will be less accurate and will need to be re-aligned. We’ve named the product “FireOptimizer” because you can easily sample traced or generated data to re-align your model and maintain maximal latency improvements.

Customer Stories
Earlier this year, we rolled out adaptive speculative execution to a few beta users and we’ve seen significant improvements in latency.
Cursor
Cursor, an AI code editor company, saw a ~2x speed improvement from FireOptimizer. This latency improvement brings crucial user experience improvements, so that users don’t have to wait to incorporate code edits.
“We leverage speculative decoding for our custom models deployed on Fireworks.ai, which power the Fast Apply and Cursor Tab features. Thanks to speculative decoding, we saw up to a 2x reduction in generation latency. Enabling speculation was “one-click” simple and the speculators are automatically tuned to the text distribution our models produce.” Sualeh Asif, Cursor’s Co-founder
Hume
Hume builds AI systems that measure and optimize for human emotional well-being. One of Hume’s products is their Empathic Voice Interface (EVI), which is an API to understand not just speech, but also tone and emotion.
“We deploy custom models on Fireworks.ai to enable low-latency tool use through our API. For many applications that use Hume, latency is essential because tools are being called in parallel during real-time voice interactions. Fireworks unlocks a lot of applications by reducing latency with speculative decoding." Janet Ho, Hume COO
Data Privacy and Security with FireOptimizer
At Fireworks, data privacy and security are our top priorities. Adaptive speculative decoding is offered through explicit customer opt-in, ensuring that your data is never traced or logged without your consent. The data used for adaptive speculative decoding is solely for optimizing your deployment and is automatically deleted afterward. These practices are contractually enforced—feel free to reach out to a Fireworks representative for more details.
Get Started with FireOptimizer
Fireworks has pioneered the systematic customization for inference with FireOptimizer in the industry. We believe the future of production AI lies in adaptation—where models and compound AI systems are precisely tailored to your unique use case, with hardware and software optimized for maximum efficiency. Adaptive speculative execution is the latest addition to Fireworks, complementing our lightning-fast inference engine and automated model tuning to deliver the best serving stack for your needs.
Adaptive speculative execution is available for users of enterprise reserved deployments at no additional cost. We’re also exploring bringing this feature to on-demand deployments on Fireworks’ public platform in the future. Meanwhile, other FireOptimizer features like customizable hardware mapping and customizable quantization are already accessible via self-service.
Contact us to enable FireOptimizer’s adaptive speculative decoding on your enterprise instance of Fireworks or get started with Fireworks on www.fireworks.ai. We can’t wait to see what you disrupt.