Fireworks.ai: Fast, Affordable, Customizable Gen AI Platform
By Fireworks.ai|8/17/2023
tl;dr Fireworks.ai releases the fast, affordable, and customizable Fireworks GenAI Platform. It enables product developers to run, fine-tune, and share Large Language Models (LLMs) to best solve your product problems. The platform provides state-of-the-art machine performance for latency-optimized and throughput-optimized settings, cost reduction (up to 20–120x lower) for affordable serving, and a customizable cookbook for tuning models for your product use cases.
Developer-Centric AI
Generative AI (GenAI) has shifted the product landscape and redefined product experiences for consumer and business-facing products. Large Language Models (LLMs) enable never-before-seen performance on tasks like document/code generation, auto-completion, chat, summarization, reranking, and retrieval-augmented generation.
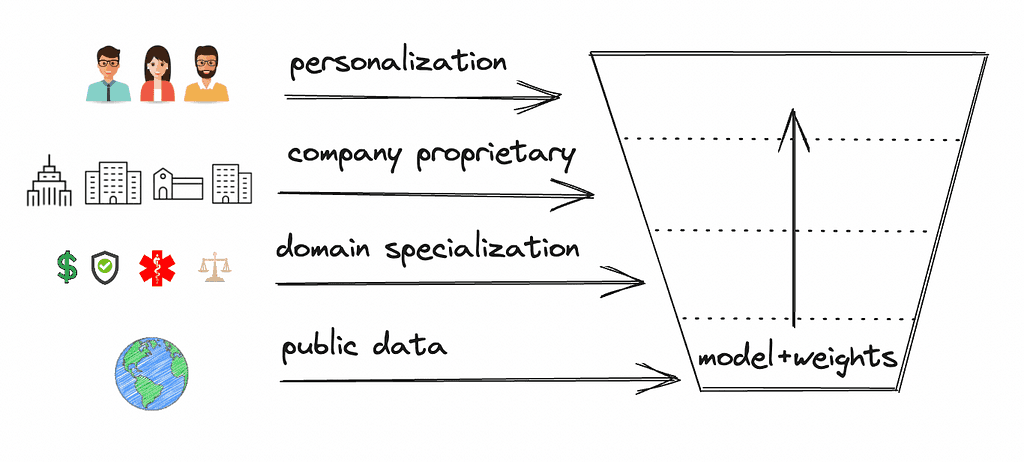
Foundation models (FMs) and parameter-efficient fine-tuning (PEFT) now enable more efficient AI customization. Instead of training large models from scratch with vast data, companies can now tailor GenAI models using open FMs like LLaMA, Falcon, and StarCoder. These FMs, sourced from internet data, serve broad tasks. But with PEFT techniques like LoRA, FMs can be customized for areas like legal or finance. Models can be customized with company data for specific tasks or personalized AI products. This approach speeds up product development and reduces data needs.
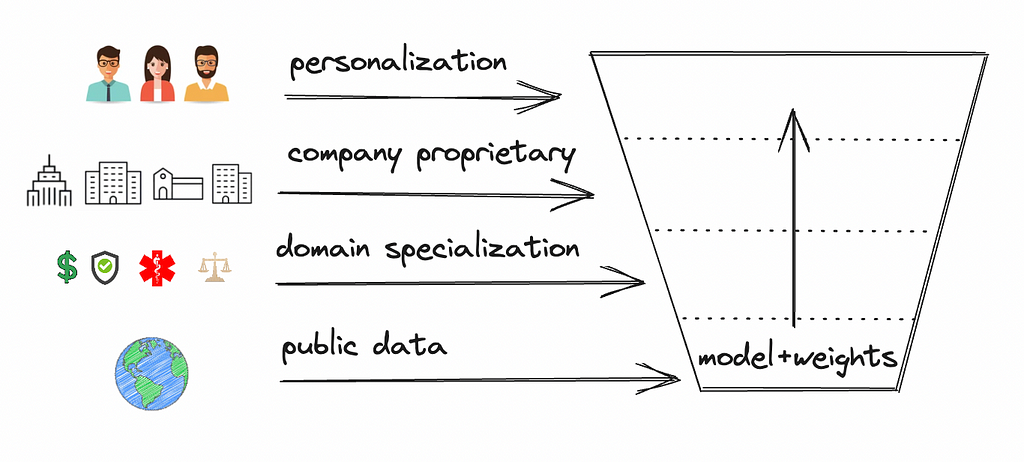
Open LLMs and PEFT enable customization of foundational LLMs for new use cases
At Fireworks, we believe in developer-centric AI: LLMs should be fast, affordable, and customizable for integration into modern products. Fireworks provides:
- A fast and affordable inference service that you can seamlessly integrate with your products with a simple API call.
- An open collection of foundational and fine-tuned models so that the community can share and easily experiment with customized LLMs without having to figure out deployment details.
- A simple and easy-to-use cookbook for fine-tuning LLMs and the ability to upload these customized models to our inference service. We aim to empower developers to integrate new AI building blocks into new and innovative products.
Fast, Affordable LLM Inference with Fireworks
Efficient Inference
Efficient inference of LLMs is an active area of research, but we are industry veterans from the PyTorch team specializing in performance optimization. We use model optimizations including multi/group query attention optimizations, sharding, quantization, kernel optimizations, CUDA graphs, and custom cross-GPU communication primitives. At the service level, we employ continuous batching, paged attention, prefill disaggregation, and pipelining to maximize throughput and reduce latency. We carefully tune deployment parameters including the level of parallelism and hardware choice for each model.
Machine efficiency improvements from our runtime allow us to pass on cost savings to the user. Compared to other providers serving similar-sized models, we offer prices that are 1–2 orders of magnitude lower. In particular, we provide special optimization for fine-tuned models, resulting in significant savings compared with OpenAI and other OSS model providers.
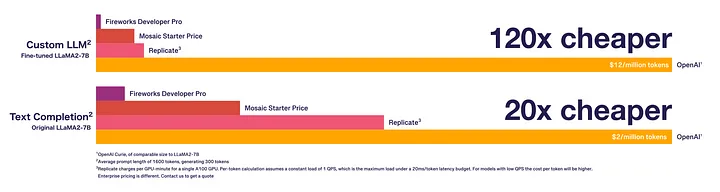
The Fireworks GenAI Platform delivers significantly lower costs than comparable providers
The Fireworks Developer tier is free to use to get you going easily. For more advanced and much higher usage, Fireworks Developer Pro pricing is based on $/input million tokens and $/output million tokens, listed in the table below. To illustrate the cost for product usage, the below study examines several common LLM use cases and the typical number of input and output tokens. We use the Fireworks per-token pricing and compute a normalized price for each use case.

In addition to cost savings, we can deliver lower latency and cost than existing solutions. For example, we compare with the popular open-source vLLM framework. Running both solutions on a lightly loaded server with 8 A100 GPUs we're getting 2–3x lower latency. Importantly, our service's latency stays low as server load increases and it can maintain 3x higher maximum throughput than vLLM while staying within the latency constraint.
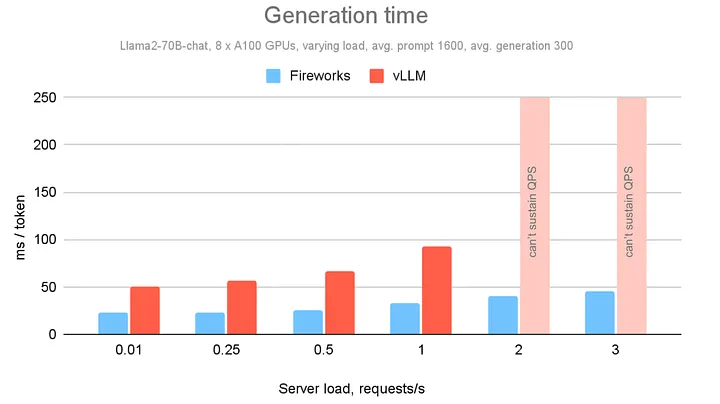
The Fireworks platform offers latency significantly lower than comparable open-source offerings
Special Serving & Performance of LoRA Tuned Models
The Fireworks Inference Service stack is built with first-class support for serving of LoRA fine-tuned models. We compose LoRA with all optimization techniques, including sharding and continuous batching. Further, we enable multi-tenancy of multiple LoRA adapters on the same base model with cross-model request batching. This brings efficiency that is not available when hosting your tuned model elsewhere. We pass these savings to you by making the cost of a fine-tuned model serving as low as the base model regardless of how much traffic it receives.
We believe this pricing is key for unlocking the power of expert models fine-tuned for a specific use case. If you have many use cases or many variants of a single model, each of the model variants might serve very few requests. Deploying each of them on a separate GPU would be prohibitively expensive on a per-token basis. With Fireworks, you can experiment with fine-tuning without breaking the bank.
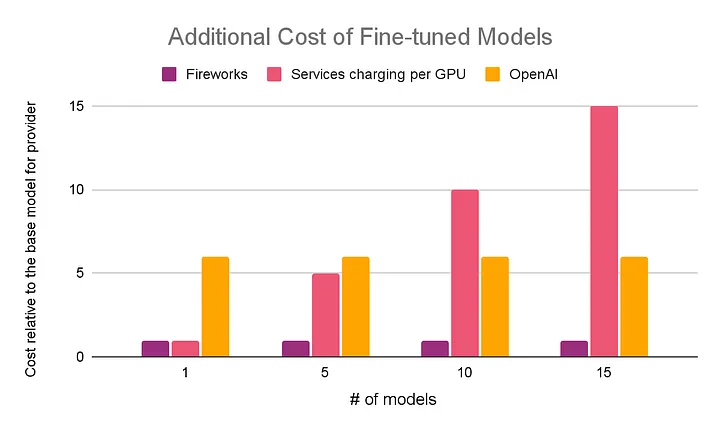
The cost of serving fine-tuned models on Fireworks does not scale with the number of models
Simple Workflow for Experimentation and Production
Simple Interfaces and APIs
Fireworks.ai provides several state-of-the-art foundational models for you to use off the shelf, including those from the LLaMA 2, Falcon, and StarCoder families. Sign up for an API key here and access the models for free today. The Fireworks console allows you to interact with models right in your browser.

Trying out LLaMAv2–70B in the Fireworks console
Programmatic API Access
Fireworks also provides a convenient REST API that allows you to call LLMs programmatically from your product. The API is OpenAI API-compatible and thus interoperates with the broader LLM ecosystem. Try out the REST API using our interactive explorer.
The Fireworks.ai API explorer helps you to test and implement LLM API calls
We also provide a dedicated Python API:
# First run: pip install fireworks-ai
import fireworks.client
fireworks.client.api_key = "\<FIREWORKS_API_KEY\>"
completion = fireworks.client.Completion.create(
model="accounts/fireworks/models/llama-v2-7b",
prompt="The quick brown fox",
)
print(completion)For applications that already use the OpenAI Python SDK, migration to Fireworks involves simply switching the API endpoint:
import openai
# Override the destination warning: it has a process-wide effect
openai.api_base = "https://api.fireworks.ai/inference/v1"
openai.api_key = "\<FIREWORKS_API_KEY\>"
# or specify them as env variables
# export OPENAI_API_BASE="https://api.fireworks.ai/inference/v1"
# export OPENAI_API_KEY="\<FIREWORKS_API_KEY\>"
chat_completion = openai.ChatCompletion.create(
model="accounts/fireworks/models/llama-v2-70b-chat",
messages=[{
"role": "system",
"content": "You are a helpful assistant."
}, {
"role": "user",
"content": "Say this is a test"
}],
temperature=0.7
)
print(chat_completion)🦜️🔗 LangChain Integration
Fireworks has partnered with LangChain to provide Fireworks integration, allowing LangChain-powered applications to use Fireworks fine-tuned and optimized models. Integrating Fireworks into your LangChain app is just a few calls away using the LLM module:
from langchain.llms.fireworks import Fireworks
api_key = "\<FIREWORKS_API_KEY\>"
model_id="accounts/fireworks/models/llama-v2-70b-chat"
llm = Fireworks(
model=model_id, max_tokens=256,
temperature=0.4, fireworks_api_key=api_key)
print(llm("Name the countries and their capitals."))Your Go-To Spot for Fine Tuned Models
Off-the-Shelf Models and Addons: We test and curate a list of top models (both in-house and from the community) for various product use cases. There are two application areas that we'd like to highlight:
- Summarization: We have released our own high-quality summarization model for distilling long documents.
- Multilingual chat: Modern chat applications work very well in English, but supporting other languages is an active area of development. We are showcasing high-quality LLaMA2 base and chat models in Korean, Traditional Chinese, and Mandarin that have gotten traction from the community.
Check out all of the latest available models on our models page.
Customization with Fireworks Fine Tuning Cookbooks
Foundational models and community-uploaded adapters are great for some cases, but in many cases, you need to customize a model based on a new task or on your own data. However, the information required to recreate these models and implement the latest modeling techniques is dispersed across various repositories, online forums, and research papers. To help with this, Fireworks provides an easy-to-use cookbook repository that allows you to fine-tune models and upload them to the Fireworks inference service.
The Fireworks cookbooks are open-source for the community to use and modify. We invite contributions to the repository to help build strong fine-tuning tools for all!
Contributing to the Community
- Share With The World: Think your custom addon is broadly useful to the community? Reach out to us and we can discuss publishing it on our models page.
- Your Idea, Your Rules: Whatever you create stays yours. We help you serve the model so you can reach many different customers.
Conclusion
We are excited to announce the Fireworks Generative AI Platform for fast, affordable, and customizable serving of the latest open Large Language Model architectures. Try the platform and see how it can help you unlock the power of Generative AI for you. Follow us on Twitter and LinkedIn and join our discord channel for more discussions!