
How Fireworks evaluates quantization precisely and interpretably
By Dmytro Dzhulgakov|8/1/2024
TL;DR
- There’s no one size fits all for quantization - There are a variety of quantization techniques and potential parts of a model to quantize. Fireworks works closely with individual customers, like Cursor and Superhuman, to tailor quantization for individual use cases
- KL divergence for measuring quantization quality - To measure quantization quality, we prefer divergence metrics - they’re highly interpretable, accurate and supported by literature
- Other evaluation methods - Fireworks carefully evaluates our models using both divergence and task-based metrics to ensure quality matches reference models. However, we advise against using task-based approaches to measure quantization quality because high noise limits precision
- You’re the best judge of quality - Different quantization techniques affect use cases differently. Therefore, end developers are ultimately the best judge of quantization quality. We’re excited about Fireworks’ industry leading combination of speed, cost and quality and encourage you to judge for yourself!
Intro
With the release of Llama 3.1, there’s been considerable discussion about the benefits and tradeoff of different quantization methods. Evaluating quantization quality is notoriously tricky, so in this post, we share how Fireworks approaches quantization and evaluates tradeoffs.
With both general LLM inference and quantization, we believe there’s no one-size-fits all solution for LLM inference. Inference and quantization set-ups are ideally tailored specially for a certain use case.
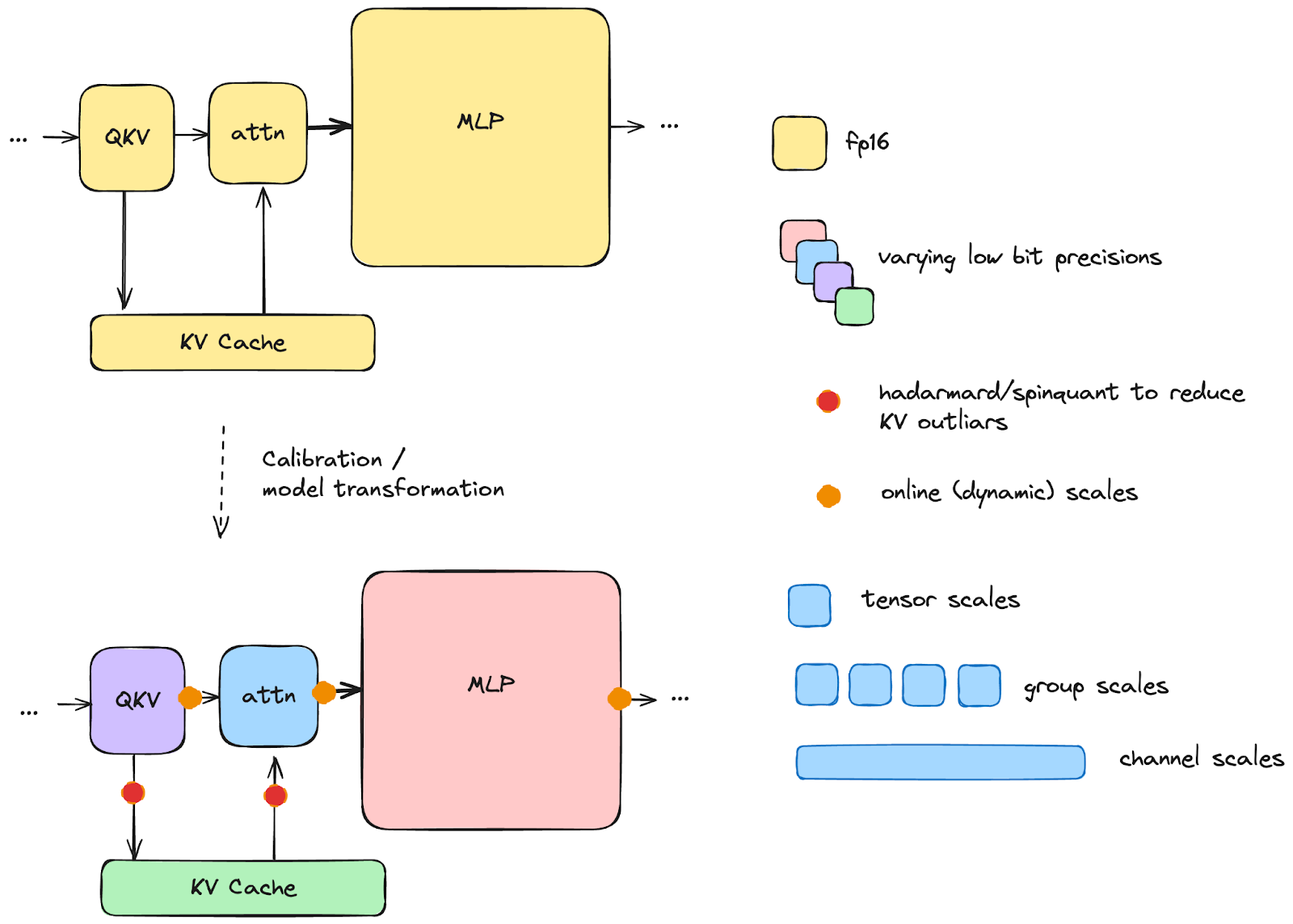
A common misunderstanding with quantization is that it’s black and white and that a model is either quantized (well) or not. However, there are both
- A wide range of possible quantization techniques, with varying levels of aggression. For example, we may use techniques such as SmoothQuant, GPTQ, and outlier reducing transforms (Hadamard, SpinQuant) to maximize the quality of the quantized model. Granularity of scaling factors may vary from one-per-entire-tensor to one-per-small-group of values. At runtime, the quantized model may use techniques such as online hadamard to reduce KV cache incoherence, or online scales for linear transformations.
- Various layers/parts of the model that may be quantized, like QKV projection, attention or KV cache. Some layers may be skipped or not.
Generally, as you increase quantization aggression level, performance improves and quality degrades. However, it’s possible to achieve disproportionate performance improvements with an insignificant effect on quality. The tradeoff between quality and performance varies based on factors including:
- (a) Specific model (or even model fine-tune)
- (b) Use case - Quantization could affect a use case like code generation differently than function calling, see hypothetical diagrams below
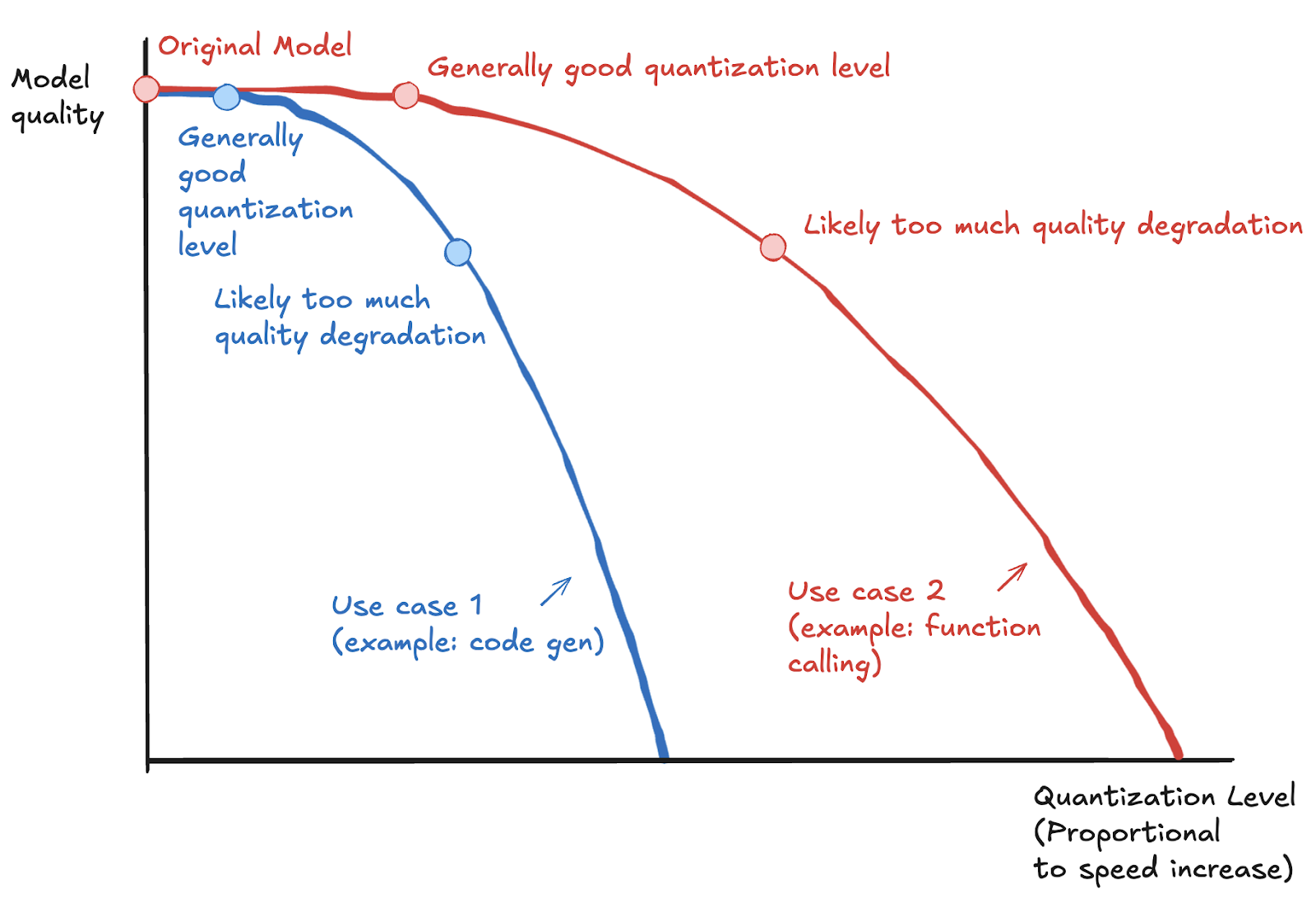
Generally, the goal with quantization is to hit a sweet spot on the Pareto curve of quality vs speed. We work with enterprise customers individually to find this spot. However, for our public endpoints there’s no one perfect configuration since there are a variety of use cases on the platform.
KL Divergence - Evaluating Quantization Quality
How should one measure model quality for quantization? Since quality is use case dependent, developers are ultimately the best judges for quality for their application. However, to measure general model quality, we prefer to focus on divergence metrics (how much the quantization changes outputs of a particular model) as opposed to pure capability metrics (i.e. how much the quantized model scores on general benchmarks like MMLU).
This idea is well described in a recent “Accuracy is Not All you Need” paper from Microsoft Research. Simply put, quantization introduces noise that can flip some right answers to wrong but also some wrong answers to right (especially when the model is “on the fence”). This skews accuracy. Focusing on changes in model probability distribution is more precise and hence gives enough resolution to interpret effects of individual quantization techniques.
Specifically we focused on two divergence metrics:
- Kullback-Leibler Divergence (KLD) - measures how much token probability distribution changes (even if the selected token in each position is still the same)
- Token rejection rate - measures how many selected top-probability tokens differ (you can think of it as an accuracy of using the quantized model as a draft model (β))
We further breakdown these metrics for prefill and generation (different parts of inference may use different quantization techniques) to understand the divergence:
- Prefill KL Divergence
- Generation KL Divergence
- Prefill Rejection Rate
- Generation Rejection Rate
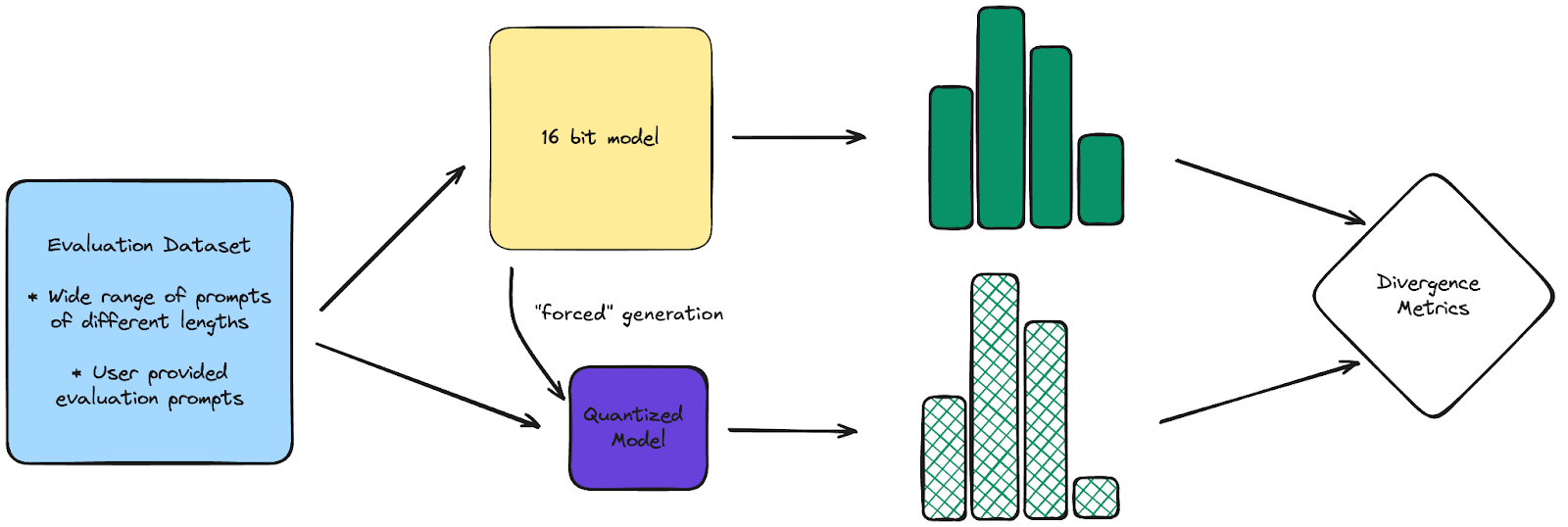
Our methodology is as follows:
- Reference model generation: To compute divergences, we ask the reference 16-bit model to generate tokens until completion across a varied set of prompts. Assuming sufficient token volume, divergence metrics are robust to the choice of the initial prompts.
- Reference distribution creation: At every position, we record the top N logprobs and normalize it to a distribution. As a rule of thumb, we pick N such that the top N tokens cover 0.99 of the distribution, and we find N=16 to be a good value.
- “Forced” quantized model generation and distribution creation: We then run a quantized model over the same prompts and construct a similar distribution. Importantly, we stick to the completions sampled from the reference model even if the quantized model prefers to choose other tokens. It guards against the quantized model generating an entirely different completion that may have poor quality but good perplexity metrics (e.g. repetitiveness).
- Divergence analysis: We can then analyze the expected divergence across all samples, expected divergence with respect to positions, etc. Importantly, we can look at these metrics for both the prefill, as well as generation, since different techniques affect each section differently.
We evaluated KL divergence on Llama 3.1 8B Instruct on 4 different “levels of quantization”, in which different parts of the model are quantized. For comparison, we also compare against MMLU. The Fireworks platform exposes logprobs, so we encourage folks to evaluate divergence results for themselves. We also encourage other providers to expose logprobs to help the community analyze quantization tradeoffs. Results are shown below.
- Level 1: Quantize MLP Matmul except first & last layer (least aggressive quantization)
- Level 2: Level 1 + quantized omitted layers and QKV
- Level 3: Level 2 + quantized KV cache
- Level 4: Level 3 + quantized attention in prefill (most aggressive quantization)
Metrics for quantization level (May not match Meta’s reported exactly due to templating differences. Bolded number is an example of a high-noise MMLU metric)
| MMLU Accuracy | Prefill KLD | Prefill Rejection Rate | Generation KLD | Generation Rejection Rate | |
|---|---|---|---|---|---|
| FP16 | 0.676328 | 0 | 0 | 1.33E-06 | 0.00015 |
| Quantization Level 1 | 0.675189 | 0.00257 | 0.0195597 | 0.00286 | 0.01743 |
| Quantization Level 2 | 0.676613 | 0.00574 | 0.0285162 | 0.00543 | 0.02396 |
| Quantization Level 3 | 0.665076 | 0.00596 | 0.028668 | 0.00772 | 0.02865 |
| Quantization Level 4 | 0.661302 | 0.01224 | 0.0425623 | 0.00796 | 0.02930 |

A few notable takeaways
- Proportionate increase in divergence with quantization: As expected, we find that the divergence metrics increase monotonically with respect to each other and to the quantization level. In contrast, the task-based metric (MMLU) is highly noisy, where we see that MMLU performance of a quantized model (level 2) actually increases compared to the FP16 reference model.
- Interpretability: Different models require different choices of quantization, as bottlenecks (both information and performance) may differ. By segmenting our metrics and running ablation tests, we can see how different types of quantization affect different aspects of inference, to inform choices about the best quantization approach. For example, we see:
- Quantizing the MLP layers of a model affects the model relatively less than quantizing QKV values.
- Quantizing attention prefill ops benefits the speed of long prefill models more than long generation models.
- Little quality degradation - It’s difficult to define singular values for acceptable divergence, but we generally see that KL divergence of < 0.007 results in high-quality deployments.
Ensuring Quality
At Fireworks, we carefully compare our deployed models to reference models, to the point of finding bugs in Hugging Face implementations. Task-based accuracy metrics like MMLU aren’t sensitive enough to differentiate between quantization types. However, they can still be helpful to run as a sanity check.
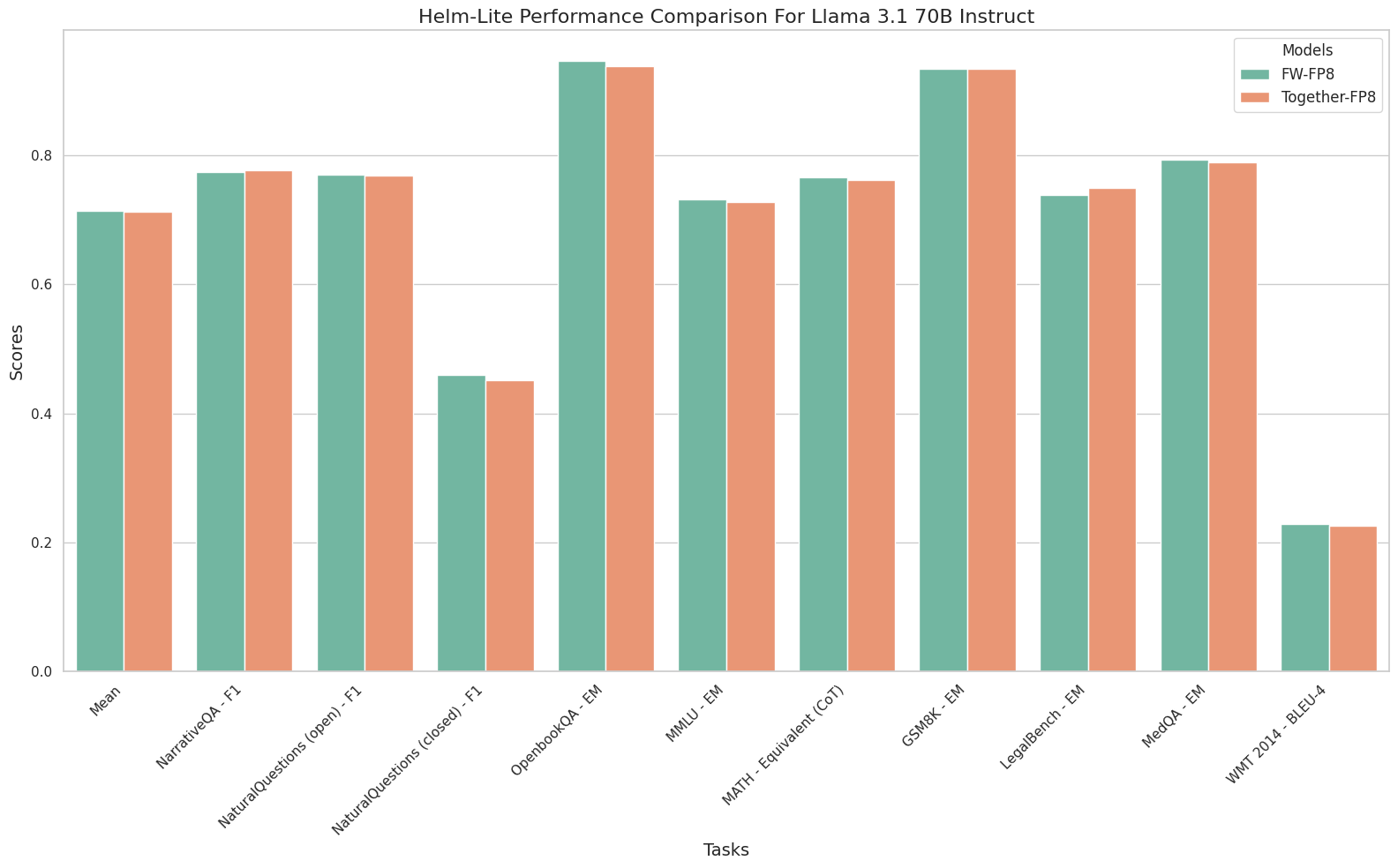
We ran the Helm-Lite evaluation suite and other tests against Llama 3.1 70B on Fireworks and Together AI’s endpoint. With the Llama 3.1 release, Meta published official reference evaluations that include fully formatted prompts, which we reproduced. We see almost no discrepancy between the models across dimensions. To try the official Meta evaluation, check out our reproduction script here.




Issues with other evaluation methods for quantization quality
Even given our strong results on MMLU and other task-based benchmarks, we advise against drawing conclusions about quantization quality from small discrepancies in these benchmarks. Task-based metrics work well for analyzing foundation model quality. However, they have poor sensitivity at comparing between quantization techniques due to noisy, all-or-nothing scoring methods.
Task-based evaluations judge correctness as a step function. Consider a situation where a reference model has a distribution of 0.51/0.49 for the correct answer vs the wrong answer. A quantized model could have a similar distribution of 0.49/0.51 but a task-based evaluation would score the model as if it had a 0/1 distribution.
This all or nothing approach leads to meaningful amounts of inaccuracy. For example, we see that quantized model quality sometimes improves on benchmarks. For example, in the below diagram from Together AI, quantized models (Turbo) results on GSM8K and MMLU EM are actually better than non-quantized models by several percentage points.
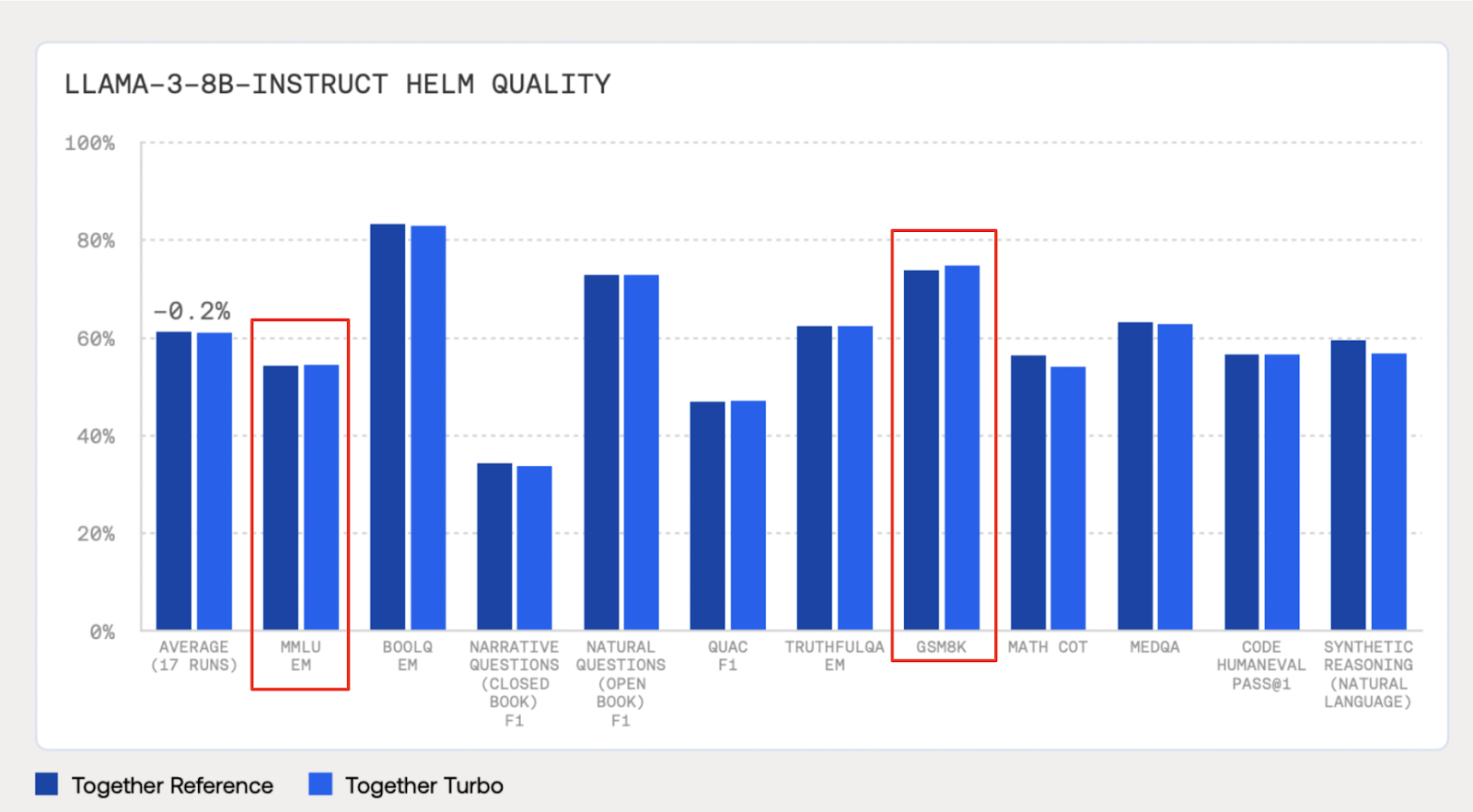
What’s happening is not a magical increase in model quality from quantization, but a reflection of noise throughout the benchmarks. The obvious high levels of noise means that takeaways drawn from small differences on benchmarks (especially < 1%) are misguided.
Perplexity
Perplexity is an aggregate metric of how well LLM models predict given text distribution. One drawback is that evaluating perplexity on a model’s own generation may produce biased results if it is “overconfident” in its outputs Additionally it suffers from averaging bias. To quote from Accuracy is Not All You Need:
“Our observation that the difference between two models’ output token values cancel out leaving the average metric result unchanged, is applicable to perplexity as well. In particular, since perplexity may be interpreted as the inverse of the geometric mean of token probabilities, lower probabilities for some tokens in the test dataset may be canceled by higher probabilities of other tokens.”
KL divergence metric described above is closely related to perplexity but addresses the two drawbacks.
AlpacaEval and LLM-as-a-judge methods
Having humans do blind voting on the preferred answer among the two produced by LLMs represents the golden standard for LLM evaluation. This approach is spearheaded by LMsys Chatbot Arena, which has counted more than 1.5M votes to date. Human evaluation is costly though, so metrics like AlpacaEval have popularized using a powerful LLM (e.g. GPT-4) to pick the preferred answer. However, this approach has limitations:
- Sample sizes is small (805 samples) leading to wide confidence intervals
- LLM-judges are biased towards more verbose generations. Alpaca Eval 2.0 aims to correct for it by fitting a regression model on human preference and applying length-based adjustment to LLM judgement. However, this correction is not specifically evaluated for smaller variations, like in quantization.
- Results may be hard to reproduce due to varying sampling settings.
- Default settings optimize for cheaper evaluation at expense of accuracy. I.e. judge LLM is prompted with a simple preference question instead of chain-of-thought.
We observe quite noisy results from this benchmark in practice with large swings in results without clear causation. For example, we observe cases where quantized models are evaluated as superior to reference models.
Arena-Hard-Auto is a newer benchmark created by the team behind LMsys Chatbot Arena itself. It aims to address limitations:
- Carefully curated and fresh prompt set that minimizes contamination
- Using chain-of-thought prompting for the judge LLM for more precise evaluation
- Technical report states much higher separability power and almost 2x smaller alignment gap with human preferences compared to AlpacaEval 2.0
We ran Arena-Hard-Auto v0.1 for Llama 3.1 405b Instruct on several quantized model configurations. There’s no clear difference, any gap is dwarfed by confidence intervals.

Conclusion
Given that quantization has different effects on different use cases, the best judge of quantization quality is ultimately the end developer. We encourage you to try both our quantized models and unquantized models (labeled “-hf”) on your use case. We quantize models for a variety of our enterprise customers to maximize speed, quality and cost for applications that reach millions of users. Roland Gavrilescu, AI lead at Superhuman, writes:
“We've been thrilled with Fireworks' FP8 models. They've enabled Superhuman to provide a better user experience by enabling low-latency and high response quality for Ask AI. The serving efficiency of the deployment enables us to deliver a stellar customer experience."
Our quantization approach enables Fireworks to deliver industry leading speed and cost. For example, we helped Cursor reach 1000 tokens/sec with their Fast Apply feature. As Sualeh Asif, Anysphere’s co-founder says:
“Fireworks has been an amazing partner getting our Fast Apply and Copilot++ models running performantly. They were a cut above other competitors we tested on performance. We’ve done extensive testing on their quantized model quality for our use cases and have found minimal degradation. Additionally, Fireworks has been a key partner to help us implement task specific speed ups and new architectures, allowing us to achieve bleeding edge performance!”
Balancing speed and quality also allowed us to release Llama 3.1 405B at 10x cost efficiency of other providers.
To check out the speed, cost efficiency and quality that Fireworks’ quantization expertise affords, try out models on Fireworks’ public platform. If you’re interested in having Fireworks help customize quantization of a model for your enterprise use case, please contact us (inquiries@fireworks.ai). At Fireworks, we’re excited to contribute to community discussion, so please reach out with any questions or suggestions for further deep dives.