LLM Inference Performance Benchmarking (Part 1)
By Fireworks.ai|11/3/2023
Optimizing Large Language Model (LLM) machine performance in inference is a complex space and no solution is one-size-fits-all. Use cases may require low latency (chatbots, coding assistants, Q&A) or high throughput (catalog creation/improvement, model evaluation); They may require processing long inputs (summarization) or short inputs (chat); Or they may require generating long outputs (code completion) or short outputs (intent classification). In this post, we explore how different use cases call for different optimization objectives and show how Fireworks provides many different deployment configurations that optimize for these cases.
Multi-faceted Problem Space for LLM Inference
For LLMs, workload characteristics vary drastically across use cases:
- Sequence length: in LLM inference, we see inputs range from under 100 to over 30,000 tokens and generation length range from under 10 to over 1000 tokens. LLM machine performance can change dramatically based on these.
- Model size: Popular LLMs range in size over 10s of billions of parameters. Optimizing a 7B parameter model may look quite different from optimizing a 70B parameter model.
- Optimization Target: Based on the product use case, LLM deployments may be optimized for throughput, latency, or cost. These objectives are also in tension with each other, as one can be traded off, for example, higher cost for lower latency, and vice versa.
Customers should take these and more factors into consideration when determining how to best evaluate an LLM solution.
Multi-faceted solution Space for LLM Inference
Given the above problem space, there are many ways LLMs can be deployed to optimize for these factors. To name a few:
- Hardware Type: Providers may serve on low-cost devices like A10g GPUs or on high-performance devices like A100 and H100. The device type has large implications on throughput, latency, and cost.
- Device Count: LLMs can be partitioned across several devices to optimize for performance. For example, LLMs may be replicated to optimize for throughput, or they may be sharded to optimize for latency, as well as various combinations of the two.
- Deployment: LLMs may be deployed in a private deployment for guaranteed performance and throughput or in a multi-tenant deployment for on-demand testing. This is important to keep in mind when evaluating LLM performance, as a public tier may not be performance-optimized and may have other customers' traffic running on it, which affects results.
Fireworks: Many LLM Deployment Configurations for Your Use Case
Given the above complexity, at Fireworks we provide many different solutions to customers based on their requirements. We offer the easy-to-use on-demand Developer PRO tier, which can be accessed via the console for no-commitment, lightweight testing of LLMs.
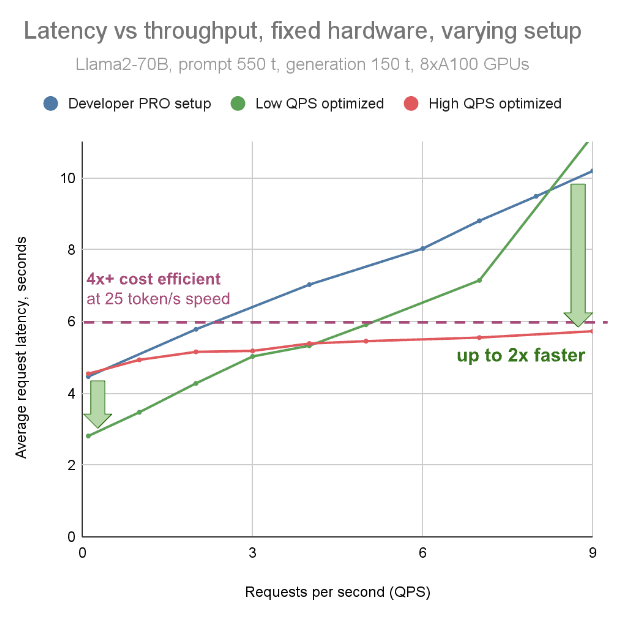
On the other end of the spectrum, we provide optimized deployments specific to customer needs. As a concrete example, the graph below examines a Llama-70B deployment with 550 input tokens and 150 output tokens, running on 8x NVIDIA A100. We explore latency at varying levels of load (QPS) for 3 deployment configurations. The baseline blue line is the Fireworks Developer PRO setup, optimized for on-demand experimentation (but which we are constantly optimizing as well). The green line shows a latency-optimized configuration, which achieves the fastest response time at low load, but sacrifices response time at higher load. Finally, the red line shows a configuration that balances latency and throughput, providing low latency across many levels of load.
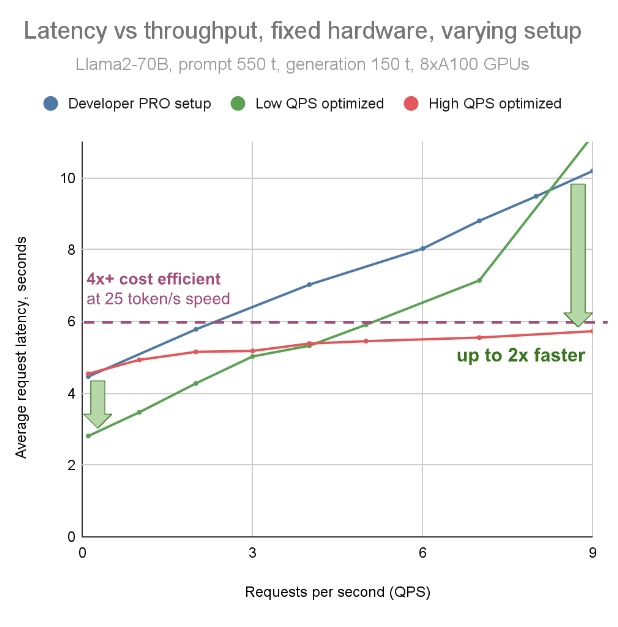
Fireworks works with customers to choose the configuration that best suits their use case.
Conclusion
There is no one-size-fits-all solution for LLM inference. Customers should keep in mind the use case requirements (e.g. input and output length), optimization objective (throughput, latency, cost) and match vendor solutions to those requirements. Try the Fireworks platform and email inquiries@fireworks.ai to inquire about optimized LLM deployments.
Getting the right tools to measure performance is crucial, too. We're releasing the benchmark suite we've been using at Fireworks to evaluate described performance tradeoffs. We hope to contribute to a rich ecosystem of knowledge and tools (e.g. those published by Databricks and Anyscale) that help customers optimize LLMs for their use cases. Stay tuned for more details about shared metrics and benchmarking experience from Fireworks in the next blog post.