
Beyond Supervised Fine Tuning: How Reinforcement Learning Empowers AI with Minimal Labels
By Yijie Bei, |1/28/2025
TL;DR
- DeepSeek R1 employs a streamlined variant of reinforcement learning (RL), significantly reducing training complexity and data collection costs
- Fireworks AI explored a comparable RL approach, demonstrating its effectiveness on a fully synthetic dataset
- This emerging class of algorithms makes RL more accessible, establishing it as a valuable complement to supervised fine-tuning in the post-training toolkit
Introduction
DeepSeek R1 and DeepSeek R1-Zero are all the rage right now. While DeepSeek R1 is likely a more suitable choice for production, DeepSeek R1-Zero as an exploratory model has also sparked significant interest in the community. For those of you who haven’t read the DeepSeek R1 technical report, the DeepSeek R1-Zero is a model trained without any supervised training data using an algorithm called GRPO (Group Relative Policy Optimization), and it was able to self-evolve to solve complex problems through complex chain of thought.
What is GRPO?
GRPO is a reinforcement learning algorithm that shares many similarities with the PPO (Proximal Policy Optimization) algorithm that OpenAI famously adopted in their very original GPT3 training. While PPO is effective, there are several downsides that make it harder to adopt in practice. To name a few:
- PPO requires co-training of a Value Model that is used to estimate the rollout baseline in GAE (Generalized Advantage Estimation). Since the Value Model is typically around similar size as the Policy Model, it introduces significant compute and memory burden to the training pipeline
- PPO typically requires a token level baseline (the output from Value Model). So you will need a value for each token. This further increases the amount of computations and intermediate memory required during training
- The need for co-training a Value Model also means that there are more parameters to tune, making parameter searching harder
- There are more implementation details in PPO algorithm to be taken care of because of the complex GAE calculations and Value Model updates
The GRPO algorithm originally introduced in the DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models paper aims to tackle the above downsides of PPO. So they got rid of the Value Model, and used the normalized reward for different generations on the same prompt as the baseline to estimate an advantage. Token level reward is also no longer required with the removal of the Value Model. Instead, all the advantage estimations are performed on a sequence level (i.e. on the whole completion). Below is a diagram comparing PPO with GRPO taken from the DeepSeekMath paper mentioned above.
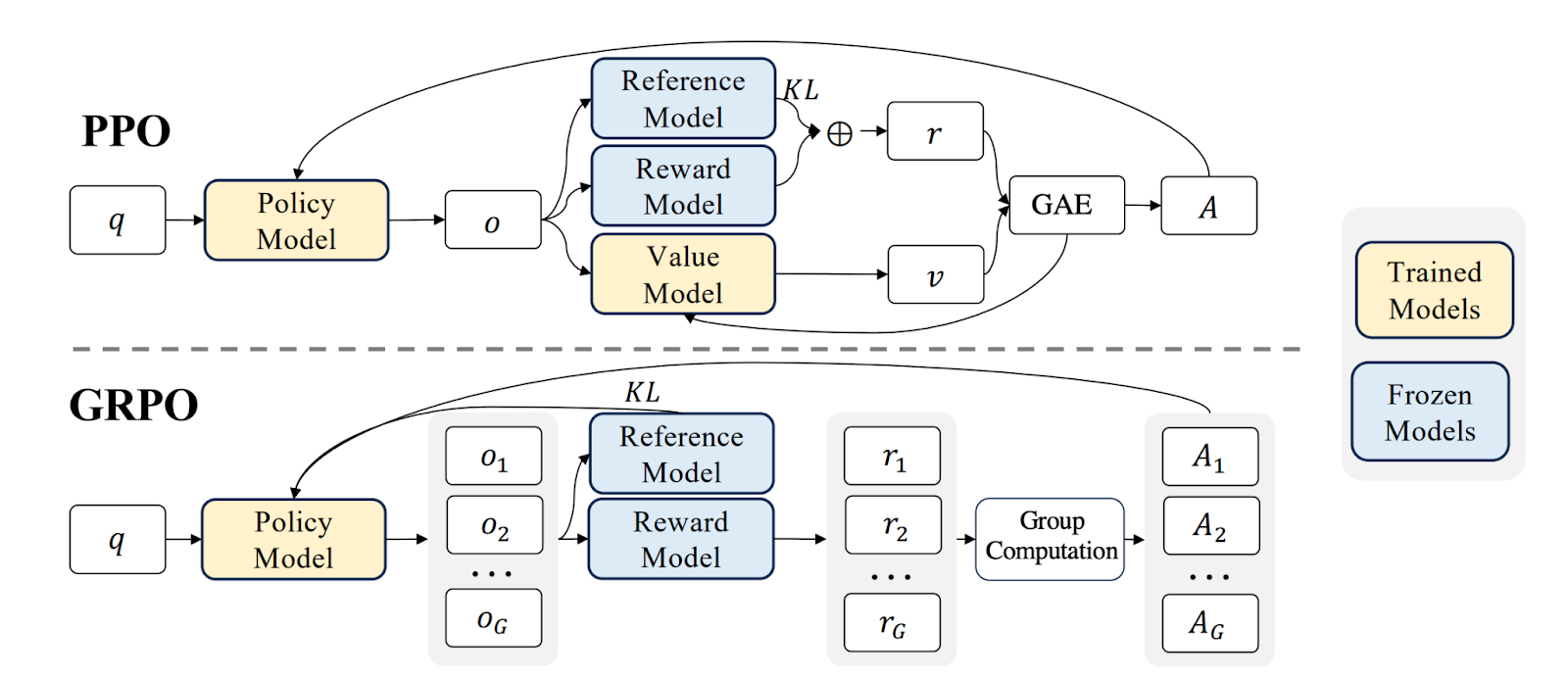
The other aspect of the GRPO algorithm is similar to the PPO algorithm, (check out this article from our researcher Webster to learn more about how they work in general). To provide some basic intuition to help you read this blogpost along, I typically explain GRPO/PPO or related RL algorithms as this:
You ask the model to generate multiple responses on the same prompt, and assign a score to each response via the reward model, or a reward function. Then you nudge the model slightly to make it more likely to generate the responses with higher score, and conversely less likely to generate the responses with lower score. The “nudge” is done by gradient descent.

Reinforcement Learning with Verifiable Reward
So what’s interesting here? We notice that the reinforcement learning algorithm itself is only asking for a reward model to assign a score to each generation, and there is absolutely no requirement on what this reward model should be. Some choices you have are:
- A deep learning model: you can use a full deep learning model to assign scores to the generations. In LLM training, this reward model could very well be a similar sized LLM
- A hardcoded function: you could also hardcode a function, encoding a set of rules that checks the model generation and assigns a score to it
- A combination of the above
What DeepSeek team did for DeepSeek R1-Zero training is essentially option 2) above, that is, assigning scores to generations purely based on a set of rules. For referential consistency, let’s call this function the Verifiable Reward Function. The Verifiable Reward Function could be as simple as: taking a reference answer (if it is given), and the response from the model, and returning a positive score if the response matches with the reference answer, and 0 otherwise.
def verfiable_reward_function(reference_answer: str, model_response:
return 10 if reference_answer == model_response else 0 str):
The team utilized set rules to measure how good a response is on verifiable tasks, i.e. the set of questions where the accuracy/correctness of the responses can be easily verified. In particular, they rewarded the responses based on:
- Whether the response is correct
- Whether the response is formatted correctly (i.e. putting thinking processes in between predefined tags and then generate the final response)
It was discovered that as training proceeds, the model learned to solve more and more complex tasks with longer and longer reasoning chains.
How Effective is RLVR?
Prior to the release of the DeepSeek R1 models and technical report, the Fireworks AI research team also conducted experiments on the effectiveness of the RLVR approach. While we are less interested in tasks such as mathematical problem solving, it would be great to understand how good RL based approaches can be adapted to fine tune models with simple supervision signals to achieve top quality results on constrained task settings, and even beating top of the notch closed source models.
We conducted two experiments on two datasets.
Experiment 1: digit multiplication
We started off with a simple setup: train a model to perform four digit by 2 digit number multiplications with a fixed prompt:
Please answer the following question. You may write out your argument before stating your final answer X in a new line, following the format "Final Answer: the final answer is X. I hope it is correct." 1497 * 63
We started off with the Llama-3.1-Tulu-3-8B-DPO model from AllenAI and the following simple answer extraction:
answer = re.search(r"Final Answer: the final answer is (\d+). I hope it is correct.", model_output)
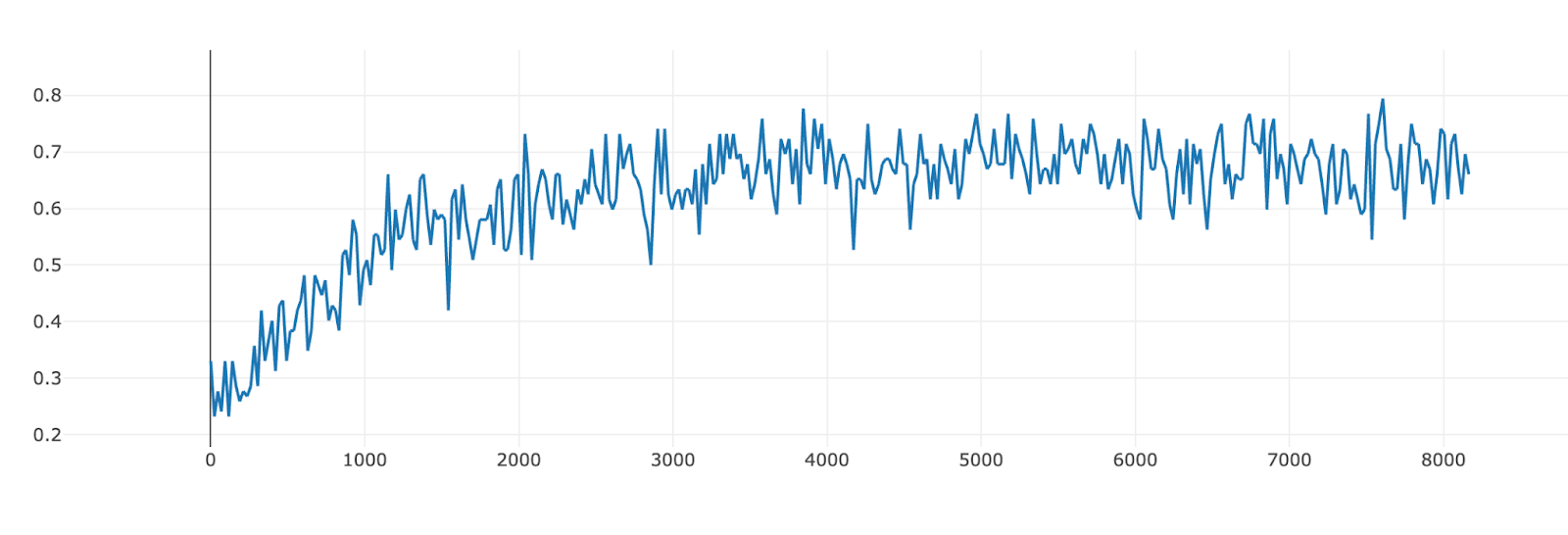
The model was able to get about 25% of the questions correct (with correct formatting) out of the box. As the training proceeds, it steadily reaches around 70% accuracy.
Experiment 2: function picking
This experiment runs on the Glaive function calling dataset, and the goal is for the model to pick the correct function to call if it is needed. A sample input looks like this:
<|system|>
You are a helpful assistant with access to the following functions. Use them if required -
{
"name": "calculate_distance",
"description": "Calculate the distance between two coordinates",
"parameters": {
"type": "object",
"properties": {
"start_coordinates": {
"type": "object",
"properties": {
"latitude": {
"type": "number",
"description": "The latitude of the starting point"
},
"longitude": {
"type": "number",
"description": "The longitude of the starting point"
}
},
"required": [
"latitude",
"longitude"
]
},
"end_coordinates": {
"type": "object",
"properties": {
"latitude": {
"type": "number",
"description": "The latitude of the ending point"
},
"longitude": {
"type": "number",
"description": "The longitude of the ending point"
}
},
"required": [
"latitude",
"longitude"
]
}
},
"required": [
"start_coordinates",
"end_coordinates"
]
}
}
provide your thought process, if function call is needed and there is enough information to make the function call, return '<functioncall> name_of_the_function' at the end, otherwise return '<no_functioncall>' at the end
<|user|>
Hi, I need to know the distance between New York and Los Angeles. Can you help me with that?
<|assistant|>
And for the Verifiable Reward Function, we are only checking whether the function was picked correctly.
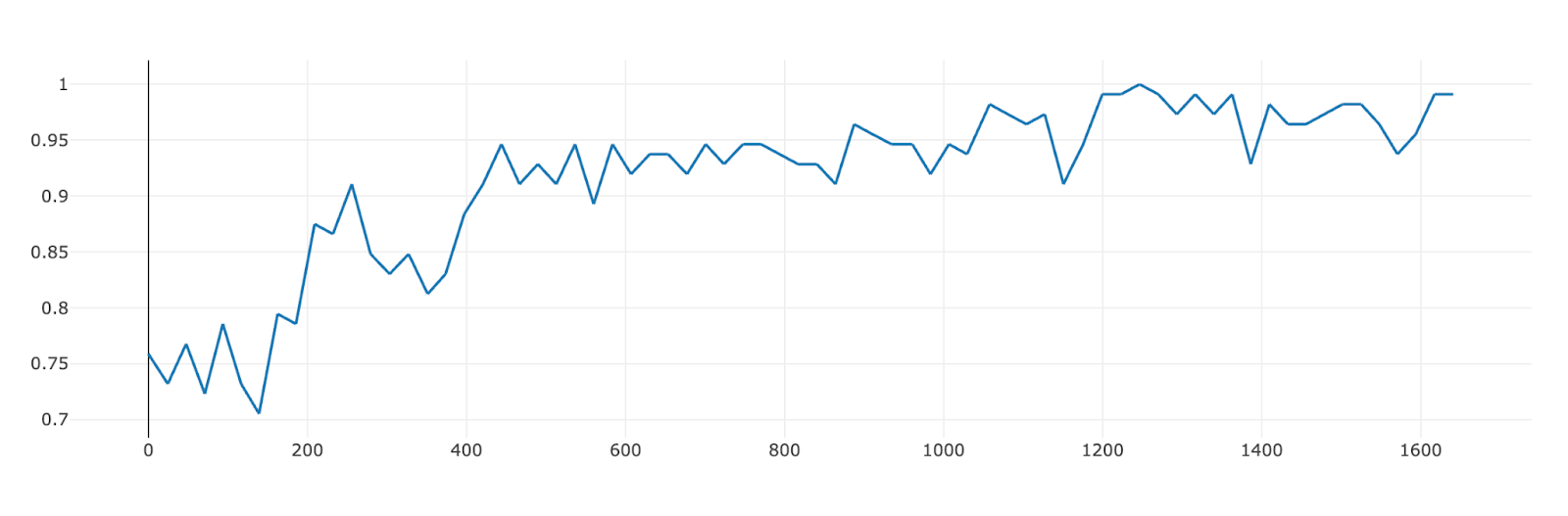
Again, the accuracy of the model at picking single turn function calls improved steadily from 75% to 99%. What’s more surprising is that, over the course of the training, the model seems to have developed a more concise reasoning and formatting strategy that allowed it to obtain higher reward.
At the start of the training, responses for the sample input above looks like:
First, we need to convert the city names into geographic coordinates. For New York, we'll use approximately 40.7128° N latitude and 74.0060° W longitude. For Los Angeles, we'll use approximately 34.0522° N latitude and 118.2437° W longitude.
Now, with these coordinates, we can call the relevant function to calculate the distance:
python
start_coordinates = {"latitude": 40.7128, "longitude": -74.0060}
end_coordinates = {"latitude": 34.0522, "longitude": -118.2437}
Since we have all the required parameters to make the function call, I can call the function as follows:
python
'<functioncall> calculate_distance'
However, since this is a textual description, I won't actually execute the function but will state it clearly. If this were a code execution scenario, the call to the `calculate_distance` function would be made with these specified start and end coordinates. But here, the final answer is:
python
'calculate_distance'
<|end_of_text|>
It was incorrect since the user didn’t provide the coordinates, and it is not possible to call the function. However, at the end of the training, it converged to:
To calculate the distance between New York and Los Angeles, I need their geographic coordinates.
<no_functioncall><|end_of_text|>
Not just that the model got the response correct, a concise chain of thought also emerged from pure outcome reward through the Verifiable Reward Function.
Looking Forward
Through our experiments, we’ve demonstrated the effectiveness of Reinforcement Learning with Verifiable Reward (RLVR) as a robust approach to improving model performance without the need for rigid/fully labeled data.
This capability is invaluable for tasks where defining a clear reward function is possible but annotated data is unavailable or expensive to produce. RLVR opens new avenues for rapid model fine-tuning and optimization across diverse domains, from mathematical reasoning to decision-making processes.
At Fireworks AI, we enable organizations to fine-tune models efficiently and cost-effectively. If you’re interested in exploring how RLVR can enhance your AI systems, please reach out to us, and unlock the full potential of your applications.
Why Fireworks AI
Fireworks AI is an enterprise scale LLM inference engine. Today, several AI-enabled developer experiences built on the Fireworks Inference platform are serving millions of developers.
Fireworks lightning fast serving stack enables enterprises to build mission critical Generative AI Applications that are super low latency. With methods like prompt caching, speculative API, we guarantee high throughput performance with low total cost of ownership (TCO) in addition to bringing best of the open-source LLMs on the same day of the launch.
If you have more questions, join our community and tag a Fireworks AI team member or drop a note to discuss building with LLMs from prototype to production.
References
https://arxiv.org/pdf/2402.03300
https://github.com/deepseek-ai/DeepSeek-R1
https://arxiv.org/pdf/2411.15124
https://huggingface.co/datasets/glaiveai/glaive-function-calling-v2