Fireworks Platform Spring 2024 Updates
By Fireworks.ai|3/1/2024
Since Fireworks’ inception in 2022, we’ve provided companies like Tome, Quora and Sourcegraph with industry-leading speed and quality for production use cases across image and text. However, much of the power of the Fireworks platform was restricted to customers in our Enterprise tier (typically $100k in compute inference volume and above). Now, we’re excited to bring this speed and flexibility to developers and businesses broadly.
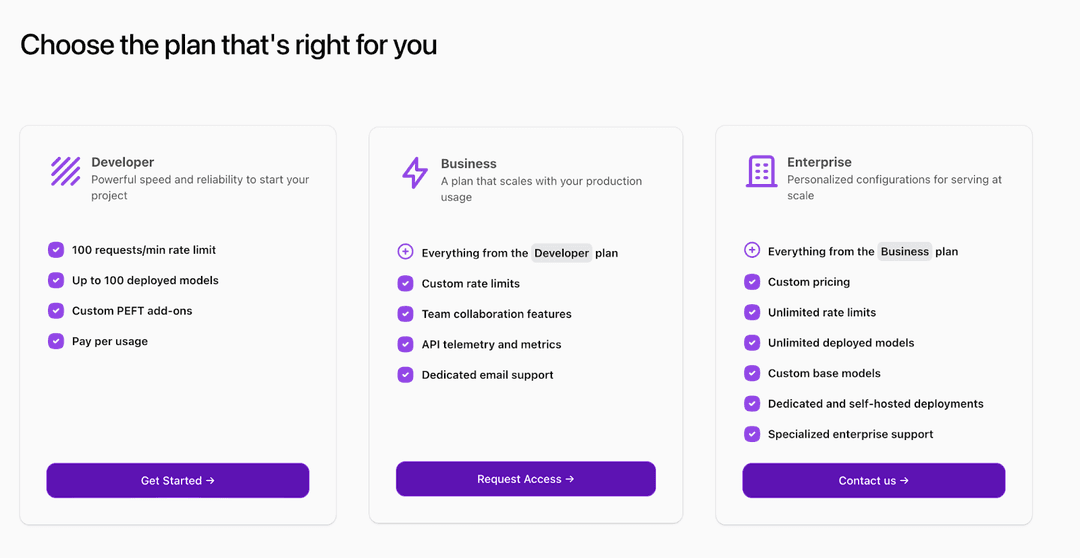
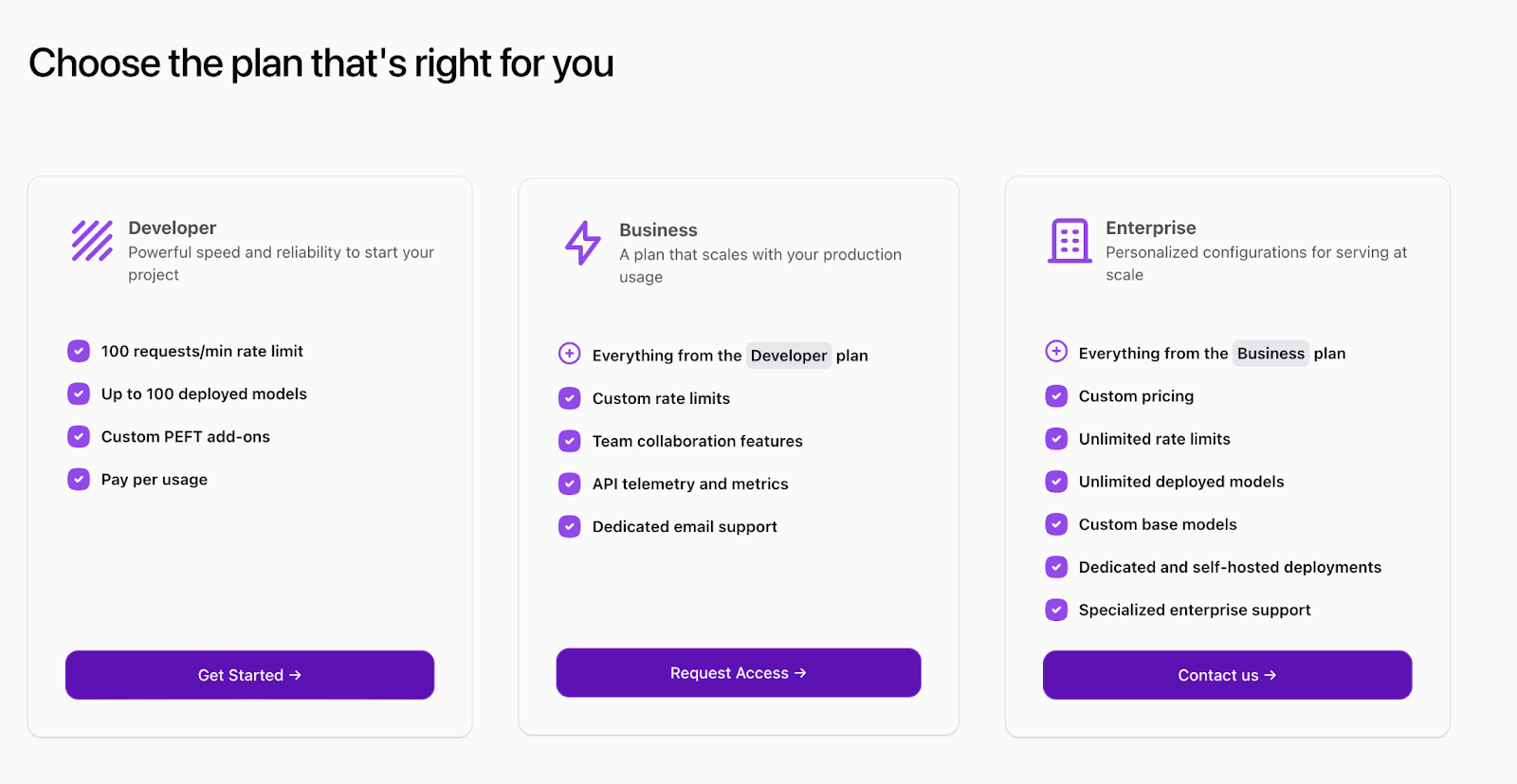
Our goal is to create the best platform for anyone to serve generative AI models in production, so we have 3 updates intended for improved usage at scale:
-
Dedicated deployments - We’re starting the rollout (waitlist link) of dedicated deployments to deploy models on your own private GPU(s) and pay per second of usage. Our proprietary serving stack enables total costs 6x lower than HuggingFace TGI and also ~2.5x the generation speed per request!
-
Improved speeds and rate limits for serverless models - Use serverless models like Mixtral with new speeds of up to 300 token/sec, cheaper pricing, and rate limits of up to 600 requests/minute
-
Post-paid billing with spend limits - Get invoiced at the end of the month instead of needing to remember to top up credits.
As part of our commitment to production serving, we’re rolling out a new Business tier of usage, with the offering currently in alpha. We want to ensure that Fireworks provides options for developers and start-ups to scale up their usage from the initial prototype all the way through to Enterprise-level traffic. The Business tier is intended to provide support and features (like custom rate limits and GPU capacity) to customers who deploy LLMs at scale but do not yet have Enterprise tier volume. Contact us at inquiries@fireworks.ai if you’re interested in trying it early!
Dedicated deployments
Until today, all configurations for models on the Fireworks public platform were “serverless” to users, meaning that servers and hardware configurations were managed by us. Today, we’re answering requests from production users for more control and flexibility by starting the rollout of dedicated deployments.
What are dedicated deployments? Dedicated deployments let you run a model on your own private GPU and pay based on GPU usage time. This gives you the power to choose both your model and hardware configuration and only pay for what you use. You can start your deployment with a simple deploy command and your deployment will be shut down automatically when you stop using it.
Why dedicated deployments? Compared to serverless models, dedicated deployments can provide
-
Guaranteed capacity and speeds - Production use cases, especially those with high traffic, often require guaranteed capacity to handle traffic spikes or latency guarantees. Before today, only businesses on a specialized enterprise plan could configure their own hardware set-up
-
Broader range of models - Dedicated deployments enable Fireworks to offer a broader range of models and will enable users to upload custom base models for improved flexibility
Why use Fireworks for dedicated deployments? Compared to competing options for dedicated deployments, Fireworks dedicated deployments offers
- Improved speed - Fireworks deployments all use the industry-leading Fireworks LLM serving stack, which offers optimal speed and quality. The serving stack was created through Fireworks’ deep Pytorch expertise and offers performance improvements compared to competing platforms, even on the same hardware.
The table below shows that Fireworks dedicated deployments offer ~3x the speed as Hugging Face Text Generation Interfaces (TGI) on the same GPU configuration of 8xA100s with Llama 70B for 1 concurrent request. The summarization use case uses 3500 input tokens and 350 output tokens while the chat use case uses 350 input tokens and 350 output tokens. H100s will also be available for even faster speeds!

Figure 1: Latency of Llama 70B on 1 concurrent request
- Throughput and price: Our speed becomes even more notable when coupled with the fact that the Fireworks’ efficient serving stack also enables higher throughput (and lower cost). The chart below shows the max throughput of 8xA100s before GPUs are overloaded. In the summarization use case, Fireworks dedicated deployments served nearly ~3.5x the requests per second of Hugging Face TGI (can serve more concurrent users) while simultaneously offering ~2.5x the generation speed per request (faster individual user experience).

Figure 2: Max throughput of Llama 70B and generation speed per request
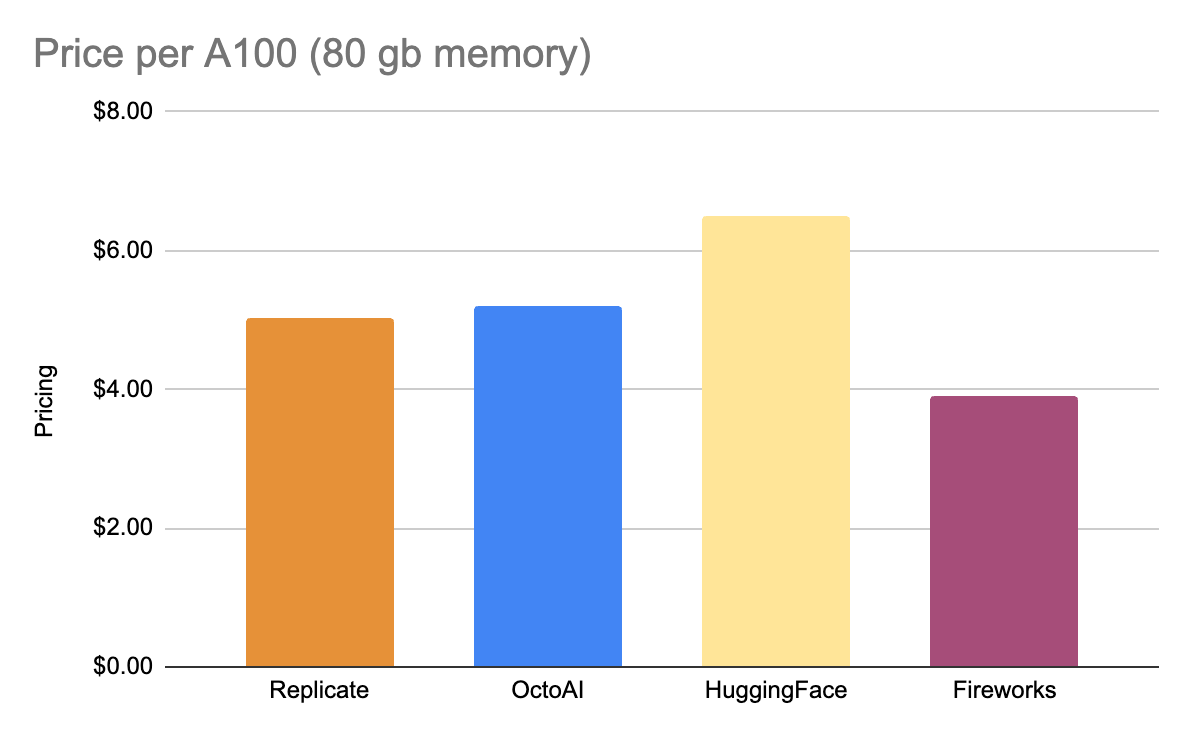
This difference is even starker given that we charge lower rates per GPU than most other inference platforms (see chart). We charge $3.89 per hour for one A100 GPU, compared to rates of $6.50 for HuggingFace Endpoints (running TGI runtime) and $5+ for other platforms. Therefore, to serve the same QPS as HuggingFace Endpoints, Fireworks deployments are 6x lower cost (0.60x cost / 3.5x QPS ) while providing ~2.5x the generation speed per request.
- Power and control: Unlike many competing platforms, Fireworks lets you choose the number of GPUs to use for a deployment. Anyone will be able to use up to 4 GPUs and Business tier users have custom GPU limits for more power and speed options.
Get Started: Access to dedicated deployments is being rolled out today via waitlist with general availability to come soon. Sign up today to get access and to provide feedback on upcoming features!
Faster models at lower costs
For users who prefer using existing “serverless” models, we’re also announcing updates for improved production usage of our most popular models.
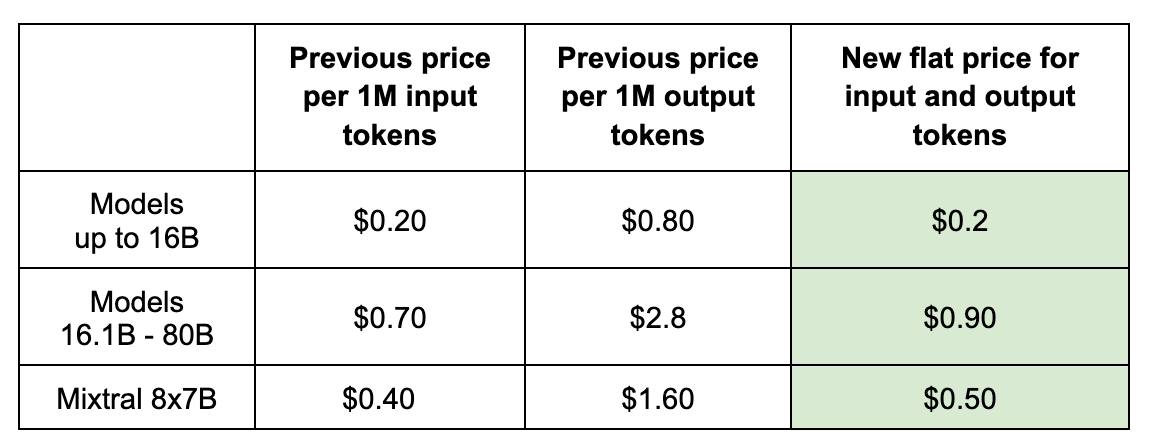
Reduced Cost - For all our language models, we’ve switched from separate pricing for input and output tokens to one flat price for all tokens (see chart). We’re making this change to have a simpler, more competitive pricing scheme. With our old pricing scheme, people would often make comparisons using output token cost, even though input tokens comprise the majority of costs in our experience.
New prices are listed in the chart below. We estimate that the change will be ~20% cheaper for the median Fireworks user. If you crunch the numbers, you’ll see that the prices are cheaper for all queries, except those with an input:output token ratio greater than ~10:1.
Improved speed: We know speed is critical for many production use cases. Users want to be able to interact quickly and don’t want to be kept waiting for responses. This is why we’re improving speed for our most popular models - Mixtral MoE 8x7b Instruct, Stable Diffusion XL variants and Llama 70b chat. We intend to provide long-term support for these models and will provide users with advanced notice before any potential, major changes in serving. We’ve made these speed improvements by updating our inference engine (like FireAttention), leveraging techniques like speculative decoding and tuning production deployment configurations.
Before these changes, we were already serving Mixtral, Stable Diffusion, and Llama 70b chat with the fastest, broadly-available speeds according to independent benchmarkers (link). Our improved Mixtral speed now reaches up to 300 tokens/sec after the first token (up from ~200 tokens/sec before) and new model latencies are shown in the chart below. See these new speeds for yourself in our redesigned model playground!
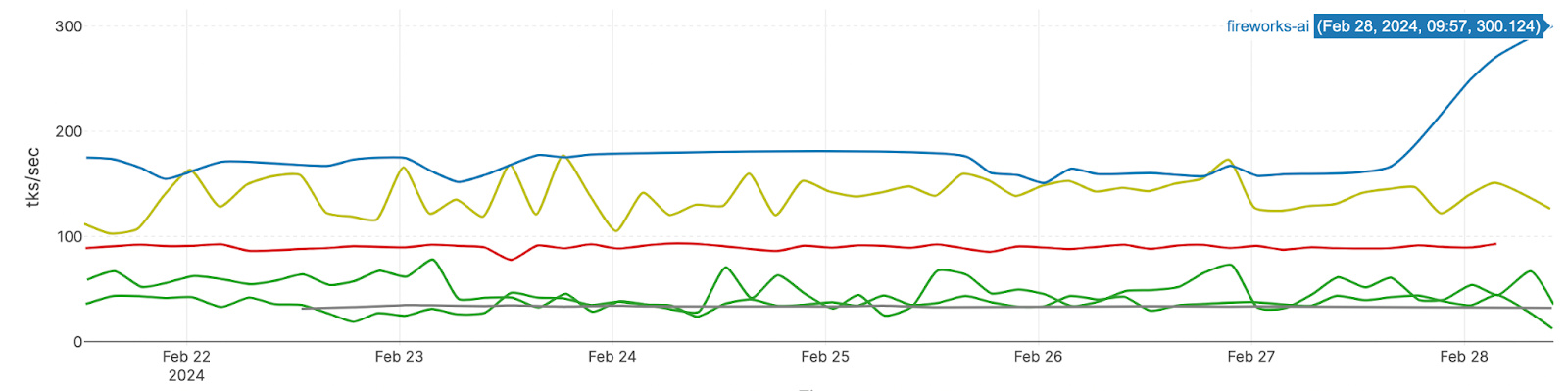
| New Latency | |
| Mixtral MoE 8x7b Instruct | Up to 300 token/sec (after the first token) |
| Llama 70B Chat | Up to 200 token/sec (after the first token) |
| Stable Diffusion XL | ~1.2 seconds for generating 1024 x 1024 30-step image |
Higher rate limits: Fireworks intends to provide first-class support to all levels of production usage, so we’re raising our rate limits. All serverless models will have rate limits of 600 requests/min by default and Business tier users will receive custom rate limits to handle even larger volumes.
Post-paid billing
Last but not least, we’re announcing a shift to post-paid billing. We’ve received much feedback from production users about how stressful it is to worry about running out of credits and how annoying it is to top up credits each week. We’re therefore switched to postpaid billing, so you just add a credit card and pay for what you use at the end of the month.
No need to worry about an astronomical bill if your app goes viral overnight either. We’ve automatically implemented monthly usage limits based on historic past spending. You can see your (1) Current invoice (2) Monthly usage limits and (3) Current monthly usage in your billing dashboard. The ability to edit your usage limit will be coming soon.
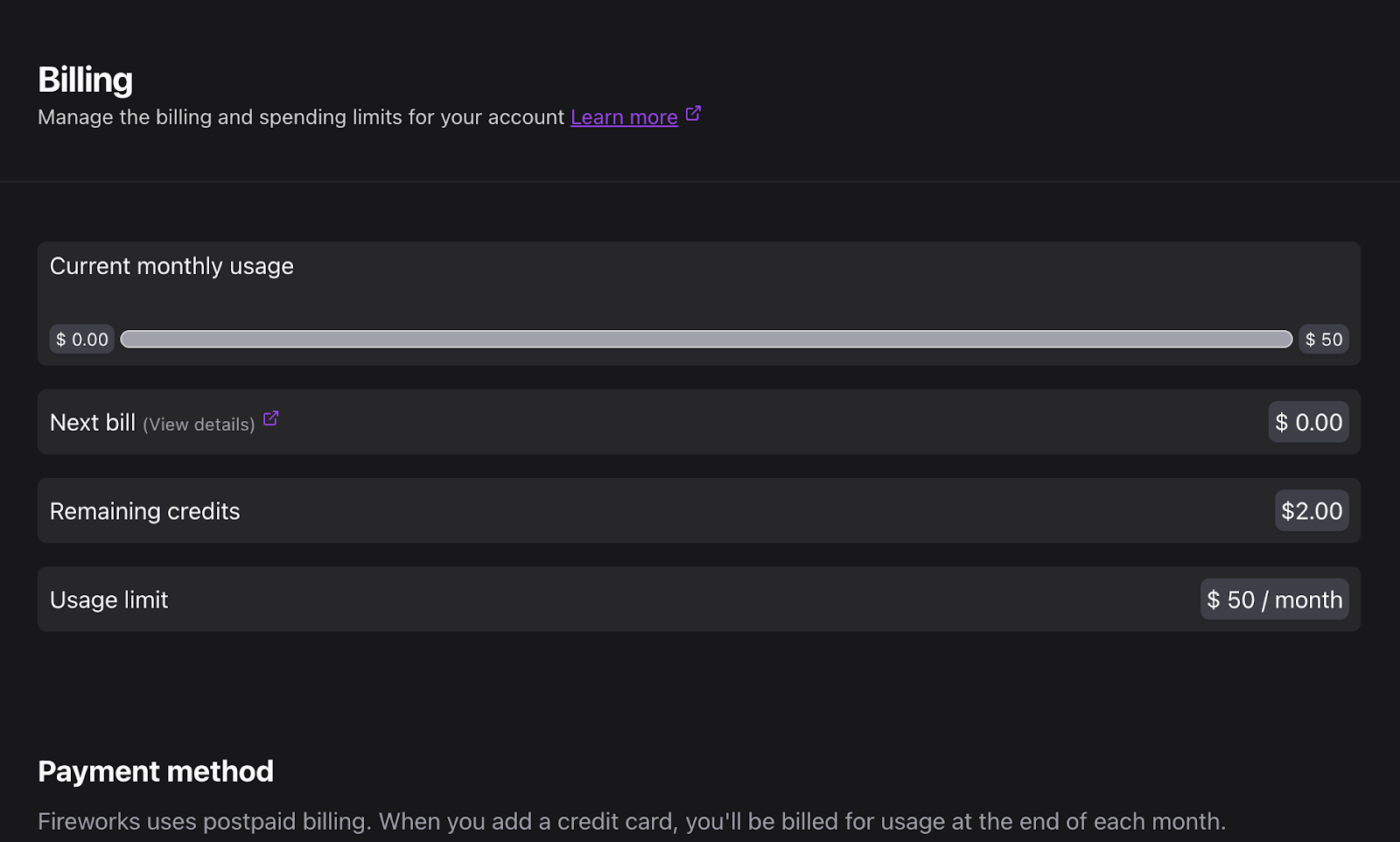
Previously purchased or gifted credits will still be linked to your account and used before post-paid billing kicks in. If you have specific questions or comments about postpaid billing, please contact us at inquiries@fireworks.ai. (Note: Users are enrolled in postpaid billing by adding their credit card). The switch to postpaid billing will be rolled out to existing Fireworks users across the next week. All new Fireworks users will immediately see the change.
Conclusion
At Fireworks, our mission is democratizing AI for developers and businesses, so we’re excited to unveil the new Business tier of usage and these production-oriented features. We’d love to hear what you think! Please connect directly with our team on Discord or Twitter.
Get started in your production journey in our models playground or directly via API. If you’re interested in dedicated deployments, please join our waitlist. We intend to provide the most performant inference service at every stage of your scaling process. If you’re a business serving LLMs at scale and are in need of fast and flexible GPU deployments, higher rate limits or have other serving needs, please contact us today to join our Business tier at inquiries@fireworks. Happy building!